
Dybe neurale netværk: hvad de er, og hvordan de fungerer
Dybe neurale netværk er et koncept, der udgør den vigtigste teknologiske arkitektur, der bruges i Deep Learning-modeller. Disse strukturer kan ikke forstås uden at forstå den generelle idé om kunstige neurale netværk, grundlæggende for kunstig intelligens.
Neurale netværk bruges til tusind ting: at genkende nummerplader, sange, ansigter, stemmer eller endda frugterne i vores køkken. De er en særlig nyttig teknologi, og på trods af at de først for nylig er blevet praktiske, vil de blive menneskehedens fremtid.
Næste Vi kommer til at se i dybden ideen om kunstige neurale netværk og dybe, at forstå hvordan de virker, hvordan de trænes og hvordan interaktionerne mellem de forskellige neuroner, der udgør dem, opstår.
- Relateret artikel: "Hvad er kognitiv videnskab? Dens grundlæggende ideer og udviklingsfaser"
Hvad er dybe neurale netværk, og hvad kendetegner dem?
Dybe neurale netværk er en af de vigtigste teknologiske arkitekturer, der bruges i Deep Learning eller Deep Learning. Disse særlige kunstige netværk har haft en svimlende vækst i de senere år, fordi de udgør et grundlæggende aspekt, når det kommer til at genkende alle slags mønstre. Kunstig intelligens eksisterer takket være driften af disse særlige netværk, som i I bund og grund kommer de til at være en kopi af, hvordan vores hjerner fungerer, selvom de er i en teknologisk og matematik.
Før vi går videre ind i, hvad dybe neurale netværk er, skal vi først forstå, hvordan kunstige neurale netværk fungerer generelt, og hvad de er til for. Lneurale netværk er en gren af "Machine Learning", som har haft en enorm indflydelse i de senere år, hjælper programmører og dataloger med at bygge ting som chatbots, der, når vi taler med dem, får os til at tro, at vi taler med rigtige mennesker.
Kunstige neurale netværk er også blevet brugt med selvkørende biler, mobilapplikationer, der genkender vores ansigt og transformerer det til det, vi ønsker, og mange flere funktioner. Dens anvendelighed er meget omfattende og tjener som grundlaget for moderne kunstig intelligens og har uendelige gavnlige anvendelser for vores daglige.
kunstige neurale netværk
Lad os forestille os, at vi er i vores køkken, og vi beslutter os for at lede efter en appelsin, en meget simpel opgave.. Vi ved, hvordan man identificerer en appelsin meget let, og vi ved også, hvordan man adskiller den fra andre frugter, som vi finder i køkkenet, såsom bananer, æbler og pærer. Som? For i vores hjerne har vi meget assimileret, hvad der er de typiske egenskaber ved en appelsin: dens dens størrelse, dens form, farven den har, hvordan den lugter... Det er alle parametre, som vi bruger til at finde en orange.
Det er en simpel opgave for mennesker, men... Kan en computer også gøre det? Svaret er ja. I princippet ville det være nok at definere de samme parametre og tildele en værdi til en node eller noget, som vi godt kunne kalde en "kunstig neuron". Vi ville fortælle den neuron, hvordan appelsiner er, med angivelse af deres størrelse, vægt, form, farve eller enhver anden parameter, som vi tilskriver denne frugt. Med denne information forventes det, at neuronen vil vide, hvordan man identificerer en appelsin, når den præsenteres for en.
Hvis vi har valgt parametrene godt, vil det være nemt for dig at skelne mellem appelsiner og ting, der ikke er appelsiner, blot ved at tage disse egenskaber i betragtning. Når den præsenteres for et billede af enhver frugt, vil den neuron søge efter egenskaberne knyttet til appelsinen og beslutte, om den skal inkluderes i kategorien "orange" eller i kategorien "andet". frugt". Statistisk set ville det være at finde et område i en parametergraf, der svarer til det, der bliver leder efter en region, der vil omfatte alle de frugtstykker, der har samme størrelse, form, farve, vægt og aroma, som appelsiner.
Umiddelbart lyder det hele meget nemt at kode, og det er det faktisk. Det fungerer meget godt at skelne en appelsin fra en banan eller et æble, da de har forskellige farver og former. Men hvad nu hvis vi præsenterede dig for en grapefrugt? og en meget stor mandarin? Det er frugter, der perfekt kan forveksles med en appelsin. Vil den kunstige neuron være i stand til selv at skelne mellem appelsiner og grapefrugter? Svaret er nej, og faktisk menes de nok at være de samme.
Problemet med kun at bruge et lag af kunstige neuroner, eller hvad der er det samme, kun at bruge simple neuroner først, er at generere meget upræcise beslutningsgrænser, når du bliver præsenteret for noget, der har mange kendetegn til fælles med det, du burde kunne genkende, men i virkeligheden er det ikke. Hvis vi præsenterer noget, der ligner en appelsin, såsom en grapefrugt, selvom det ikke er den frugt, vil det identificere det som sådan.
Disse beslutningsgrænser, hvis de er repræsenteret i form af en graf, vil altid være lineære. Brug af en enkelt kunstig neuron, det vil sige en enkelt knude, der har integrerede parametre konkrete, men ikke kan lære ud over dem, opnås meget tætte beslutningsgrænser. diffuse. Dens vigtigste begrænsning er, at den bruger to statistiske metoder, specifikt multiclass regression og logistisk regression, hvilket betyder, at når man er i tvivl, inkluderer den noget, som ikke er, hvad vi forventede, det skulle være. vil identificere.
Hvis vi skulle opdele alle frugter i "appelsiner" og "ikke appelsiner", med kun én neuron, er det klart, at bananer, pærer, æbler, vandmeloner og enhver frugt, der ikke svarer i størrelse, farve, form, aroma og så videre med appelsiner, jeg ville sætte dem i "nej" kategorien. appelsiner”. Men grapefrugter og mandariner ville placere dem i kategorien "appelsiner", hvilket gør det arbejde, som de er designet dårligt til.
Og når vi taler om appelsiner og grapefrugter, kunne vi godt tale om hunde og ulve, høns og høns, bøger og notesbøger... Alle Disse situationer er tilfælde, hvor en simpel serie af "hvis..." ("hvis...") ikke ville være tilstrækkelig til klart at skelne mellem det ene og det andet. Andet. Der er behov for et mere komplekst, ikke-lineært system, som er mere præcist, når det kommer til at skelne mellem forskellige elementer. Noget der tager højde for, at der mellem lighederne kan være forskelle. Det er her, neurale netværk kommer ind.
Flere lag, mere lig den menneskelige hjerne
Kunstige neurale netværk er, som navnet antyder, beregningsmæssige kunstige modeller inspireret af i den menneskelige hjernes neurale netværk, netværk der i virkeligheden efterligner dette organs funktion biologiske. Dette system er inspireret af neural funktion, og dets hovedanvendelse er genkendelse af mønstre af alle slags: ansigtsidentifikation, stemmegenkendelse, fingeraftryk, håndskrift, nummerplader… Mønstergenkendelse virker til næsten alt..
Da der er forskellige neuroner, er de anvendte parametre forskellige, og der opnås en højere grad af præcision. Disse neurale netværk er systemer, der giver os mulighed for at adskille elementer i kategorier, når de forskellen kan være subtil og adskille dem på en ikke-lineær måde, noget som ellers ville være umuligt at gøre måde.
Med en enkelt node, med en enkelt neuron, er det, der gøres, når man håndterer informationen, en multiklasse-regression. Ved at tilføje flere neuroner, da hver af dem har sin egen ikke-lineære aktiveringsfunktion, som oversat til et enklere sprog får dem til at have beslutningsgrænser, der er mere præcis, idet den er grafisk repræsenteret i en buet form og tager højde for flere karakteristika, når der skelnes mellem "appelsiner" og "ikke appelsiner", for at fortsætte med det eksempel.
Krumningen af disse beslutningsgrænser vil direkte afhænge af, hvor mange lag af neuroner vi tilføjer til vores neurale netværk. Disse lag af neuroner, som gør systemet mere komplekst og mere præcist, er i virkeligheden dybe neurale netværk. I princippet gælder det, at jo flere lag af dybe neurale netværk vi har, jo mere nøjagtigt og ens vil programmet være sammenlignet med den menneskelige hjerne.
Kort sagt er neurale netværk intet andet end et intelligent system, der gør det muligt at træffe mere præcise beslutninger, på en meget lignende måde, som vi mennesker gør det. Mennesker er baseret på erfaring og lærer af vores omgivelser. For eksempel, hvis vi vender tilbage til tilfældet med appelsin og grapefrugt, hvis vi aldrig har set en, vil vi perfekt forveksle det med en appelsin. Når vi er blevet fortrolige med det, vil det være så, når vi allerede ved, hvordan man identificerer det og adskiller det fra appelsiner.
Det første, der gøres, er at give nogle parametre til de neurale netværk, så de ved, hvordan det er, som vi ønsker, at det skal lære at identificere. Så kommer indlærings- eller træningsfasen, så den bliver mere og mere præcis og gradvist har en mindre fejlmargin. Dette er tidspunktet, hvor vi vil præsentere vores neurale netværk med en appelsin og andre frugter. I træningsfasen får de sager, hvor de er orange og sager, hvor de ikke er orange, for at se om de har svaret rigtigt og fortælle dem det rigtige svar.
Vi vil forsøge at gøre adskillige forsøg og så tæt på virkeligheden som muligt.. På denne måde hjælper vi det neurale netværk med at fungere, når der kommer virkelige tilfælde, og det ved, hvordan det skal skelne ordentligt, på samme måde som et menneske ville gøre i det virkelige liv. Hvis træningen har været tilstrækkelig, har man valgt gode genkendelsesparametre og har klassificeret godt, vil det neurale netværk have en meget høj succesrate for mønstergenkendelse. høj.
- Du kan være interesseret i: "Hvordan virker neuroner?"
Hvad er de, og hvordan fungerer de præcist?
Nu hvor vi har set den generelle idé om, hvad neurale netværk er, og vi kommer til at forstå mere fuldstændigt, hvad de er og hvordan disse emulatorer af neuronerne i den menneskelige hjerne arbejder, og hvor maler dybe neurale netværk i alt dette behandle.
Lad os forestille os, at vi har følgende neurale netværk: vi har tre lag af kunstige neuroner. Lad os sige, at det første lag har 4 neuroner eller noder, det andet 3, og det sidste kun har 2. Dette er alt sammen et eksempel på et kunstigt neuralt netværk, ret let at forstå.
Det første lag er det, der modtager dataene., altså den information, der godt kan komme i form af lyd, billede, aromaer, elektriske impulser... Denne første lag er inputlaget og er ansvarlig for at modtage alle data for senere at kunne sende dem til følgende lag. Under træningen af vores neurale netværk vil dette være det lag, som vi først skal arbejde med og give det data, som vi vil bruge til at se, hvor god du er til at forudsige eller identificere de oplysninger, du får giver.
Det andet lag i vores hypotetiske model er det skjulte lag, som sidder lige i midten af det første og sidste lag., som om vores neurale netværk var en sandwich. I dette eksempel har vi kun ét skjult lag, men der kan være lige så mange, vi vil. Vi kunne tale om 50, 100, 1000 eller endda 50.000 lag. I bund og grund er disse skjulte lag den del af det neurale netværk, som vi ville kalde det dybe neurale netværk. Jo større dybde, jo mere komplekst er det neurale netværk.
Til sidst har vi det tredje lag i vores eksempel, som er outputlaget. Dette lag, som navnet indikerer, er ansvarlig for at modtage information fra de foregående lag, træffe en beslutning og give os et svar eller resultat.
I det neurale netværk er hver kunstig neuron forbundet med alle de følgende. I vores eksempel, hvor vi har kommenteret, at vi har tre lag med 4, 3 og 2 neuroner, er de 4 i inputlaget forbundet med 3 i det skjulte lag og 3 i det skjulte lag med 2 i output, hvilket giver os i alt 18 forbindelser.
Alle disse neuroner er forbundet med dem i det næste lag, og sender informationen i input->skjult->output-retningen.. Hvis der var flere skjulte lag, ville vi tale om et større antal forbindelser, der sender informationen fra skjult lag til skjult lag, indtil det når outputlaget. Outputlaget, når det har modtaget informationen, hvad det vil gøre, er at give os et resultat baseret på den information, det har modtaget, og dets måde at behandle det på.
Når vi træner vores algoritme, det vil sige vores neurale netværk, vil denne proces, som vi lige har forklaret, blive udført mange gange. Vi skal levere nogle data til netværket, vi skal se, hvad resultatet giver os, og vi skal analysere det og sammenligne det med det, vi forventede, at resultatet ville give os. Hvis der er stor forskel på, hvad der forventes, og hvad der opnås, betyder det, at der er en høj fejlmargin, og at det derfor er nødvendigt at foretage et par modifikationer.
Hvordan fungerer kunstige neuroner?
Nu skal vi forstå den individuelle funktion af de neuroner, der arbejder i et neuralt netværk. Neuronet modtager et input af information fra den forrige neuron. Lad os sige, at denne neuron modtager tre informationsinput, som hver kommer fra de tre neuroner i det foregående lag. Til gengæld genererer denne neuron output, lad os i dette tilfælde sige, at den kun er forbundet med en neuron i det næste lag.
Hver forbindelse, som denne neuron har med de tre neuroner i det foregående lag, bringer en "x"-værdi, som er den værdi, som den forrige neuron sender os.; og den har også en værdi "w", som er vægten af denne forbindelse. Vægt er en værdi, som hjælper os til at give en forbindelse større betydning frem for andre. Kort sagt, hver forbindelse med de tidligere neuroner har en "x" og en "w" værdi, som multipliceres (x·w).
Det skal vi også have en værdi kaldet "bias" eller bias repræsenteret med "b", som er antallet af fejl, der tilskynder visse neuroner til at aktivere lettere end andre. Derudover har vi en aktiveringsfunktion i neuronet, hvilket er det, der gør dens grad af klassificering af forskellige elementer (s. appelsiner) er ikke lineær. I sig selv har hver neuron forskellige parametre at tage hensyn til, hvilket gør, at hele systemet, dette er det neurale netværk, klassificeres på en ikke-lineær måde.
Hvordan ved neuronen, om den skal aktiveres eller ej? altså hvornår ved man om man skal sende information til næste lag? Nå, denne beslutning er styret af følgende ligning:
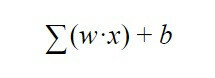
Denne formel kommer til at betyde, at summen af alle vægtene "w" ganget med alle værdierne af "x", som neuronen modtager fra det forrige lag, skal laves. Hertil tilføjes bias "b".
Resultatet af denne ligning sendes til en aktiveringsfunktion, som simpelthen er en funktion, der fortæller os, at hvis resultatet af denne ligning er større end a et bestemt antal, vil neuronen sende et signal til det næste lag, og hvis det er mindre, vil det ikke at sende det Så det er sådan en kunstig neuron beslutter, om den skal sende information til neuronerne som følger: lag ved hjælp af et output, som vi vil kalde "y", et output, der igen er input "x" af følgende neuron.
Og hvordan træner man et helt netværk?
Det første, der gøres, er at levere data til det første lag, som vi tidligere har kommenteret. Dette lag vil sende information til de følgende lag, som er de skjulte lag eller det dybe neurale netværk. Neuronerne i disse lag aktiveres eller ej afhængigt af den modtagne information. Til sidst vil outputlaget give os et resultat, som vi vil sammenligne med den værdi, vi ventede på, for at se, om det neurale netværk har lært, hvad det skal gøre korrekt.
Hvis han ikke lærte godt, vil vi udføre en anden interaktion, dvs. vi vil præsentere dig for information igen og se, hvordan det neurale netværk opfører sig. Afhængigt af de opnåede resultater vil "b"-værdierne blive justeret, det vil sige bias af hver neuron, og "w", dette er vægten af hver forbindelse med hver neuron for at reducere fejlen. For at finde ud af, hvor stor den fejl er, skal vi bruge en anden ligning, som er følgende:
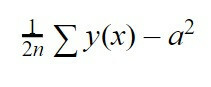
Denne ligning er den gennemsnitlige kvadratiske fejl. Vi vil gøre summen af y (x), som er den værdi, som vores netværk gav os i interaktionen minus "a", som er den værdi, som vi forventede, at det ville give os, hævet til firkanten. Til sidst skal vi gange denne sum med 1/2n, hvilket er "n" antallet af interaktioner, som vi har sendt for at træne vores neurale netværk.
Antag for eksempel, at vi har følgende værdier

Den første kolonne "y (x)" repræsenterer, hvad vores netværk har givet os i hver af de fire interaktioner, som vi har testet det. De værdier, vi har opnået, svarer som det kan ses ikke til værdierne i anden kolonne "a", som er de ønskede værdier for hver af de testede interaktioner. Den sidste kolonne repræsenterer fejlen for hver interaktion.
Anvendelse af den førnævnte formel og brug af disse data her, husk på, at i dette tilfælde n = 4 (4 interaktioner) giver os en værdi på 3,87, som er den gennemsnitlige kvadratfejl, som vores neurale netværk har i disse øjeblikke. At kende fejlen, hvad vi skal gøre nu er, som vi har kommenteret før, at ændre bias og vægte af hver enkelt af neuronerne og deres interaktioner med den hensigt, at på denne måde fejlen er reducere.
På dette tidspunkt ansøger ingeniører og dataloger en algoritme kaldet gradient descent hvormed de kan opnå værdier for at teste og ændre bias og vægt af hver kunstig neuron således at der på denne måde opnås en stadig mindre fejl, der nærmer sig forudsigelsen eller resultatet ønskede. Det er et spørgsmål om at teste og jo flere interaktioner der laves, jo mere træning bliver der og jo mere lærer netværket.
Når først det neurale netværk er tilstrækkeligt trænet, vil det være, når det vil give os nøjagtige og pålidelige forudsigelser og identifikationer. På dette tidspunkt vil vi have et netværk, der i hver af sine neuroner vil have en værdi på defineret vægt, med en kontrolleret bias og med en beslutningskapacitet, der vil gøre systemet arbejde.
Bibliografiske referencer:
- Puig, A. [AMP Tech] (2017, 28. juli). Hvordan fungerer neurale netværk? [Videofil]. Genvundet fra https://www.youtube.com/watch? v=IQMoglp-fBk&ab_channel=AMPTech
- Santaolalla, J. [Giv dig selv en vlog] (2017, 11. april) CienciaClip Challenge - Hvad er neurale netværk? [Videofil]. https://www.youtube.com/watch? v=rTpr6DuY4LU&ab_channel=DateunVlog
- Schmidhuber, J. (2015). "Dyb læring i neurale netværk: et overblik". Neurale netværk. 61: 85–117. arXiv: 1404.7828. doi: 10.1016/j.neunet.2014.09.003. PMID 25462637. S2CID 11715509

