डीप न्यूरल नेटवर्क: वे क्या हैं और कैसे काम करते हैं
डीप न्यूरल नेटवर्क एक अवधारणा है जो डीप लर्निंग मॉडल में उपयोग की जाने वाली मुख्य तकनीकी संरचना का गठन करती है। आर्टिफिशियल इंटेलिजेंस के लिए मौलिक, कृत्रिम तंत्रिका नेटवर्क के सामान्य विचार को समझे बिना इन संरचनाओं को नहीं समझा जा सकता है।
तंत्रिका नेटवर्क का उपयोग हजारों चीजों के लिए किया जाता है: लाइसेंस प्लेट, गाने, चेहरे, आवाज, या यहां तक कि हमारे रसोईघर में फलों को पहचानना। वे एक विशेष रूप से उपयोगी तकनीक हैं और इस तथ्य के बावजूद कि वे हाल ही में व्यावहारिक हुए हैं, वे मानवता का भविष्य बनने जा रहे हैं।
अगला हम कृत्रिम तंत्रिका नेटवर्क और गहरे के विचार को गहराई से देखने जा रहे हैं, यह समझना कि वे कैसे काम करते हैं, उन्हें कैसे प्रशिक्षित किया जाता है और उन्हें बनाने वाले विभिन्न न्यूरॉन्स के बीच परस्पर क्रिया कैसे होती है।
- संबंधित लेख: "संज्ञानात्मक विज्ञान क्या है? इसके मूल विचार और विकास के चरण"
गहरे तंत्रिका नेटवर्क क्या हैं और उनकी क्या विशेषता है?
गहरे तंत्रिका नेटवर्क हैं डीप लर्निंग या डीप लर्निंग में उपयोग किए जाने वाले सबसे महत्वपूर्ण तकनीकी आर्किटेक्चर में से एक. इन विशेष कृत्रिम नेटवर्कों में हाल के वर्षों में आश्चर्यजनक वृद्धि हुई है क्योंकि जब सभी प्रकार के पैटर्न को पहचानने की बात आती है तो वे एक मौलिक पहलू का गठन करते हैं। आर्टिफिशियल इंटेलिजेंस इन विशेष नेटवर्कों के संचालन के लिए मौजूद है, जो कि, में संक्षेप में, वे इस बात की प्रतिकृति बन जाते हैं कि हमारा दिमाग कैसे काम करता है, हालाँकि एक तकनीकी और गणित।
गहरे तंत्रिका नेटवर्क क्या हैं, इसमें आगे जाने से पहले, हमें पहले यह समझने की जरूरत है कि कृत्रिम तंत्रिका नेटवर्क सामान्य रूप से कैसे काम करते हैं और वे किस लिए हैं। एलतंत्रिका नेटवर्क "मशीन लर्निंग" की एक शाखा है जिसका हाल के वर्षों में बहुत बड़ा प्रभाव पड़ा है, प्रोग्रामर और कंप्यूटर वैज्ञानिकों को चैटबॉट जैसी चीजें बनाने में मदद करना, जब हम उनसे बात करते हैं, तो हमें लगता है कि हम वास्तविक इंसानों से बात कर रहे हैं।
सेल्फ-ड्राइविंग कारों के साथ कृत्रिम तंत्रिका नेटवर्क का भी उपयोग किया गया है, मोबाइल एप्लिकेशन जो हमारे चेहरे को पहचानते हैं और इसे हम जो चाहते हैं उसमें बदल देते हैं और बहुत कुछ कार्य करता है। इसकी प्रयोज्यता बहुत व्यापक है, जो आधुनिक आर्टिफिशियल इंटेलिजेंस के आधार के रूप में कार्य करती है और हमारे दिन-प्रतिदिन के लिए अंतहीन लाभकारी उपयोग करती है।
कृत्रिम तंत्रिका प्रसार
आइए कल्पना करें कि हम अपनी रसोई में हैं और हम एक नारंगी, एक बहुत ही सरल कार्य की तलाश करने का निर्णय लेते हैं।. हम बहुत आसानी से एक संतरे की पहचान करना जानते हैं और हम यह भी जानते हैं कि रसोई में पाए जाने वाले केले, सेब और नाशपाती जैसे अन्य फलों से इसे कैसे अलग किया जाए। जैसा? क्योंकि हमारे मस्तिष्क में हमने बहुत आत्मसात कर लिया है कि संतरे के विशिष्ट गुण क्या हैं: इसके इसका आकार, इसका आकार, इसका रंग, इसकी गंध कैसी है... ये सभी पैरामीटर हैं जिनका उपयोग हम किसी को खोजने के लिए करते हैं नारंगी।
इंसानों के लिए यह आसान काम है, लेकिन... क्या कंप्यूटर भी ऐसा कर सकता है? उत्तर है, हाँ। सिद्धांत रूप में, यह उन्हीं मापदंडों को परिभाषित करने के लिए पर्याप्त होगा और एक नोड या कुछ ऐसा मान निर्दिष्ट करेगा जिसे हम "कृत्रिम न्यूरॉन" कह सकते हैं। हम उस न्यूरॉन को बताएंगे कि संतरे किस तरह के होते हैं, जो उनके आकार, वजन, आकार, रंग या किसी अन्य पैरामीटर को दर्शाता है जिसे हम इस फल के लिए जिम्मेदार ठहराते हैं। यह जानकारी होने के बाद, यह उम्मीद की जाती है कि न्यूरॉन को पता चल जाएगा कि एक नारंगी के साथ पेश किए जाने पर एक नारंगी की पहचान कैसे करें।
यदि हमने मापदंडों को अच्छी तरह से चुना है, तो आपके लिए केवल उन विशेषताओं को ध्यान में रखकर संतरे और उन चीजों के बीच अंतर करना आसान होगा जो संतरे नहीं हैं। जब किसी फल की छवि प्रस्तुत की जाती है, तो वह न्यूरॉन विशेषताओं की खोज करेगा नारंगी से जुड़ा है और तय करें कि इसे "नारंगी" श्रेणी में शामिल करना है या "अन्य" श्रेणी में फल"। सांख्यिकीय दृष्टि से, यह एक पैरामीटर ग्राफ में एक क्षेत्र खोजना होगा जो कि होने के अनुरूप है एक ऐसे क्षेत्र की तलाश में है जिसमें फलों के सभी टुकड़े शामिल हों जो समान आकार, आकार, रंग, वजन और सुगंध साझा करते हों संतरे।
सबसे पहले यह सब कोड के लिए बहुत आसान लगता है, और वास्तव में यह है। यह एक संतरे को केले या सेब से अलग करने के लिए बहुत अच्छी तरह से काम करता है, क्योंकि उनके अलग-अलग रंग और आकार होते हैं। हालाँकि, क्या होगा अगर हम आपको एक अंगूर भेंट करें? और एक बहुत बड़ी कीनू? ये ऐसे फल हैं जिन्हें संतरे के साथ पूरी तरह से भ्रमित किया जा सकता है। क्या कृत्रिम न्यूरॉन अपने आप संतरे और अंगूर के बीच अंतर कर पाएगा? जवाब नहीं है, और वास्तव में उन्हें शायद वही माना जाता है।
कृत्रिम न्यूरॉन्स की केवल एक परत का उपयोग करने में समस्या, या जो समान है, केवल पहले साधारण न्यूरॉन्स का उपयोग करना, वह है जब आप किसी ऐसी चीज के साथ प्रस्तुत होते हैं, जिसमें आपको पहचानने में सक्षम होना चाहिए, तो कई विशेषताओं के साथ बहुत ही अनिश्चित निर्णय सीमाएँ उत्पन्न होती हैंहै, लेकिन वास्तव में ऐसा नहीं है। अगर हम संतरे की तरह दिखने वाली कोई चीज पेश करते हैं, जैसे अंगूर, भले ही वह वह फल न हो, तो वह उसकी पहचान कर लेगा।
ये निर्णय सीमाएँ, यदि उन्हें एक ग्राफ़ के रूप में दर्शाया जाता है, तो वे हमेशा रैखिक होंगी। एक एकल कृत्रिम न्यूरॉन का उपयोग करना, यानी एक एकल नोड जिसमें एकीकृत पैरामीटर हैं ठोस, लेकिन उनसे आगे नहीं सीख सकते, बहुत करीबी निर्णय सीमाएँ प्राप्त की जाएँगी। फैलाना। इसकी मुख्य सीमा यह है कि यह दो सांख्यिकीय विधियों का उपयोग करता है, विशेष रूप से मल्टीक्लास रिग्रेशन और लॉजिस्टिक प्रतिगमन, जिसका अर्थ है कि जब संदेह होता है तो इसमें कुछ ऐसा शामिल होता है जो वह नहीं होता है जिसकी हम अपेक्षा करते हैं। पहचान करेगा।
यदि हम केवल एक न्यूरॉन का उपयोग करके सभी फलों को "संतरे" और "संतरे नहीं" में विभाजित करें, तो यह स्पष्ट है कि केले, नाशपाती, सेब, तरबूज और कोई भी फल जो आकार, रंग, आकार, सुगंध और इतने पर संतरे के साथ मेल नहीं खाता है, मैं उन्हें "नहीं" श्रेणी में रखूंगा। संतरे"। हालांकि, चकोतरे और कीनू उन्हें "संतरे" श्रेणी में डाल देंगे, जिस काम के लिए उन्हें खराब तरीके से डिजाइन किया गया है।
और जब हम संतरे और अंगूर के बारे में बात करते हैं तो हम कुत्तों और भेड़ियों, मुर्गियों और मुर्गियों, किताबों और नोटबुक के बारे में बात कर सकते हैं... सभी ये स्थितियाँ ऐसे मामले हैं जिनमें "ifs..." ("if...") की एक सरल श्रृंखला एक और दूसरे के बीच स्पष्ट रूप से अंतर करने के लिए पर्याप्त नहीं होगी। अन्य। एक अधिक जटिल, गैर-रैखिक प्रणाली की आवश्यकता होती है, जो विभिन्न तत्वों के बीच अंतर करने की बात आने पर अधिक सटीक होती है। कुछ ऐसा जो इस बात को ध्यान में रखता है कि समानताओं के बीच मतभेद हो सकते हैं. यहीं पर तंत्रिका नेटवर्क आते हैं।
अधिक परतें, मानव मस्तिष्क के समान
कृत्रिम तंत्रिका नेटवर्क, जैसा कि उनके नाम से पता चलता है, कम्प्यूटेशनल कृत्रिम मॉडल से प्रेरित हैं मानव मस्तिष्क के तंत्रिका नेटवर्क में, नेटवर्क जो वास्तव में इस अंग के कामकाज की नकल करते हैं जैविक। यह प्रणाली तंत्रिका कार्यप्रणाली से प्रेरित है और इसका मुख्य अनुप्रयोग की मान्यता है सभी प्रकार के पैटर्न: चेहरे की पहचान, आवाज की पहचान, फिंगरप्रिंट, लिखावट, अनुज्ञा प्लेट… पैटर्न पहचान लगभग हर चीज के लिए काम करती है।.
जैसा कि विभिन्न न्यूरॉन्स हैं, लागू होने वाले पैरामीटर विभिन्न हैं और उच्च स्तर की सटीकता प्राप्त की जाती है। ये तंत्रिका नेटवर्क ऐसे सिस्टम हैं जो हमें वस्तुओं को श्रेणियों में अलग करने की अनुमति देते हैं जब अंतर सूक्ष्म हो सकता है, उन्हें गैर-रैखिक तरीके से अलग करना, कुछ ऐसा जो अन्यथा करना असंभव होगा तरीका।
एक नोड के साथ, एक न्यूरॉन के साथ, सूचना को संभालने के दौरान क्या किया जाता है एक मल्टीक्लास रिग्रेशन है। अधिक न्यूरॉन्स जोड़कर, क्योंकि उनमें से प्रत्येक का अपना गैर-रैखिक सक्रियण कार्य होता है, जिसे सरल भाषा में अनुवादित किया जाता है, जिससे उनकी निर्णय सीमाएँ होती हैं उस उदाहरण के साथ जारी रखने के लिए "संतरे" और "संतरे नहीं" के बीच अंतर करते समय अधिक सटीक, घुमावदार आकार में ग्राफिक रूप से प्रतिनिधित्व किया जा रहा है और अधिक विशेषताओं को ध्यान में रखा जा रहा है।
इन निर्णय सीमाओं की वक्रता सीधे तौर पर इस बात पर निर्भर करेगी कि हम अपने तंत्रिका नेटवर्क में न्यूरॉन्स की कितनी परतें जोड़ते हैं। न्यूरॉन्स की वे परतें, जो सिस्टम को अधिक जटिल और अधिक सटीक बनाती हैं, वास्तव में, गहरे तंत्रिका नेटवर्क हैं। सिद्धांत रूप में, हमारे पास गहरे तंत्रिका नेटवर्क की जितनी अधिक परतें होंगी, मानव मस्तिष्क की तुलना में उतना ही सटीक और समान कार्यक्रम होगा।
संक्षेप में, तंत्रिका नेटवर्क इससे ज्यादा कुछ नहीं हैं एक बुद्धिमान प्रणाली जो अधिक सटीक निर्णय लेने की अनुमति देती है, ठीक उसी तरह जैसे हम मनुष्य इसे करते हैं. मनुष्य अनुभव पर आधारित है, हमारे पर्यावरण से सीख रहा है। उदाहरण के लिए, संतरे और अंगूर के मामले में वापस जा रहे हैं, अगर हमने कभी किसी को नहीं देखा है, तो हम इसे नारंगी समझने की गलती करेंगे। जब हम इससे परिचित हो जाते हैं, तो यह तब होगा जब हम पहले से ही जानते हैं कि इसे कैसे पहचाना जाए और इसे संतरे से कैसे अलग किया जाए।
पहला काम जो किया जाता है वह तंत्रिका नेटवर्क को कुछ पैरामीटर देना है ताकि वे जान सकें कि ऐसा क्या है जिसे हम पहचानना सीखना चाहते हैं। इसके बाद सीखने या प्रशिक्षण का चरण आता है, ताकि यह तेजी से सटीक हो और उत्तरोत्तर त्रुटि का एक छोटा सा मार्जिन हो। यह वह समय है जब हम अपने तंत्रिका नेटवर्क को नारंगी और अन्य फलों के साथ पेश करेंगे। प्रशिक्षण चरण में उन्हें ऐसे मामले दिए जाएंगे जिनमें वे नारंगी हैं और ऐसे मामले जिनमें वे नारंगी नहीं हैं, यह देखने के लिए कि क्या उन्होंने अपना उत्तर सही दिया है और उन्हें सही उत्तर बता रहे हैं।
हम कई प्रयास करने की कोशिश करेंगे और जितना संभव हो वास्तविकता के करीब होंगे।. इस तरह हम वास्तविक मामलों के आने पर तंत्रिका नेटवर्क को संचालित करने में मदद कर रहे हैं और यह जानता है कि कैसे ठीक से भेदभाव करना है, ठीक उसी तरह जैसे एक इंसान वास्तविक जीवन में करता है। यदि प्रशिक्षण पर्याप्त रहा है, तो अच्छे मान्यता मापदंडों को चुना गया है और अच्छी तरह से वर्गीकृत किया है, तंत्रिका नेटवर्क में बहुत उच्च पैटर्न मान्यता सफलता दर होने वाली है। उच्च।
- आपकी इसमें रुचि हो सकती है: "न्यूरॉन्स कैसे काम करते हैं?"
वे क्या हैं और वे वास्तव में कैसे काम करते हैं?
अब जब हमने सामान्य विचार देख लिया है कि तंत्रिका नेटवर्क क्या हैं और हम और अधिक पूरी तरह से समझने जा रहे हैं कि वे क्या हैं और कैसे हैं मानव मस्तिष्क के न्यूरॉन्स के ये एमुलेटर काम करते हैं और इस सब में गहरे तंत्रिका नेटवर्क कहां पेंट करते हैं प्रक्रिया।
आइए कल्पना करें कि हमारे पास निम्नलिखित तंत्रिका नेटवर्क हैं: हमारे पास कृत्रिम न्यूरॉन्स की तीन परतें हैं। मान लीजिए कि पहली परत में 4 न्यूरॉन्स या नोड हैं, दूसरे में 3 और आखिरी में केवल 2 हैं। यह सब एक कृत्रिम तंत्रिका नेटवर्क का एक उदाहरण है, जिसे समझना काफी आसान है।
पहली परत वह है जो डेटा प्राप्त करती है।, अर्थात्, वह जानकारी जो ध्वनि, छवि, सुगंध, विद्युत आवेगों के रूप में अच्छी तरह से आ सकती है... यह पहले परत इनपुट परत है, और बाद में इसे निम्नलिखित को भेजने में सक्षम होने के लिए सभी डेटा प्राप्त करने के प्रभारी हैं परतें। हमारे तंत्रिका नेटवर्क के प्रशिक्षण के दौरान, यह वह परत होगी जिसके साथ हम पहले काम करने जा रहे हैं, इसे दे रहे हैं वह डेटा जिसका उपयोग हम यह देखने के लिए करेंगे कि आप भविष्यवाणी करने या आपको दी गई जानकारी की पहचान करने में कितने अच्छे हैं देता है।
हमारे काल्पनिक मॉडल की दूसरी परत छिपी हुई परत है, जो पहली और आखिरी परतों के ठीक बीच में बैठती है।, जैसे कि हमारा तंत्रिका नेटवर्क एक सैंडविच हो। इस उदाहरण में हमारे पास केवल एक छिपी हुई परत है, लेकिन जितनी चाहें उतनी परतें हो सकती हैं। हम 50, 100, 1000 या 50,000 परतों के बारे में बात कर सकते हैं। संक्षेप में, ये छिपी हुई परतें तंत्रिका नेटवर्क का हिस्सा हैं जिसे हम गहरे तंत्रिका नेटवर्क कहते हैं। गहराई जितनी अधिक होगी, तंत्रिका नेटवर्क उतना ही अधिक जटिल होगा।
अंत में हमारे पास हमारे उदाहरण की तीसरी परत है जो आउटपुट परत है। यह परत, जैसा कि इसके नाम से पता चलता है, पिछली परतों से जानकारी प्राप्त करने, निर्णय लेने और हमें उत्तर या परिणाम देने का प्रभारी होता है.
तंत्रिका नेटवर्क में प्रत्येक कृत्रिम न्यूरॉन निम्नलिखित सभी से जुड़ा होता है। हमारे उदाहरण में, जहां हमने टिप्पणी की है कि हमारे पास 4, 3 और 2 न्यूरॉन्स की तीन परतें हैं, इनपुट परत की 4 हैं छिपी हुई परत के 3 के साथ जुड़ा हुआ है, और छिपी हुई परत के 3 आउटपुट के 2 के साथ, हमें कुल 18 दे रहा है सम्बन्ध।
ये सभी न्यूरॉन अगली परत के साथ जुड़े हुए हैं, इनपुट->छिपा->आउटपुट दिशा में सूचना भेजते हैं।. यदि अधिक छिपी हुई परतें होतीं, तो हम बड़ी संख्या में कनेक्शन के बारे में बात करते, छिपी हुई परत से छिपी हुई परत तक सूचना भेजते हुए जब तक कि यह आउटपुट परत तक नहीं पहुंच जाती। आउटपुट लेयर, एक बार जानकारी प्राप्त करने के बाद, यह जो करेगी वह हमें प्राप्त हुई जानकारी और इसे संसाधित करने के तरीके के आधार पर परिणाम देगी।
जब हम अपने एल्गोरिद्म यानी अपने तंत्रिका नेटवर्क को प्रशिक्षित कर रहे होते हैं, तो यह प्रक्रिया जो हमने अभी बताई है वह कई बार होने वाली है। हम नेटवर्क को कुछ डेटा देने जा रहे हैं, हम यह देखने जा रहे हैं कि परिणाम हमें क्या देता है और हम इसका विश्लेषण करने जा रहे हैं और इसकी तुलना उस परिणाम से करने जा रहे हैं जिसकी हमें उम्मीद थी। यदि अपेक्षित और प्राप्त की गई राशि के बीच एक बड़ा अंतर है, तो इसका मतलब है कि त्रुटि का एक उच्च मार्जिन है और इसलिए, कुछ संशोधन करना आवश्यक है।
कृत्रिम न्यूरॉन्स कैसे काम करते हैं?
अब हम तंत्रिका नेटवर्क के भीतर काम करने वाले न्यूरॉन्स की अलग-अलग कार्यप्रणाली को समझने जा रहे हैं। न्यूरॉन पिछले न्यूरॉन से सूचना का एक इनपुट प्राप्त करता है। मान लीजिए कि यह न्यूरॉन तीन सूचना इनपुट प्राप्त करता है, प्रत्येक पिछली परत के तीन न्यूरॉन्स से आता है। बदले में, यह न्यूरॉन आउटपुट उत्पन्न करता है, इस मामले में मान लीजिए कि यह केवल अगली परत के न्यूरॉन से जुड़ा है।
पिछली परत के तीन न्यूरॉन्स के साथ इस न्यूरॉन का प्रत्येक कनेक्शन एक "x" मान लाता है, जो कि वह मूल्य है जो पिछला न्यूरॉन हमें भेज रहा है।; और इसका एक मान "w" भी है, जो इस संबंध का भार है। वजन एक मूल्य है जो हमें एक संबंध को दूसरे से अधिक महत्व देने में मदद करता है। संक्षेप में, पिछले न्यूरॉन्स के साथ प्रत्येक कनेक्शन में "x" और "w" मान होते हैं, जो गुणा (x·w) होते हैं।
हमें भी होने वाला है "पूर्वाग्रह" या पूर्वाग्रह नामक मान "बी" के साथ दर्शाया गया है जो त्रुटि की संख्या है जो कुछ न्यूरॉन्स को दूसरों की तुलना में अधिक आसानी से सक्रिय करने के लिए प्रोत्साहित करती है. इसके अलावा, हमारे पास न्यूरॉन के भीतर एक सक्रियण कार्य है, जो विभिन्न तत्वों के वर्गीकरण की डिग्री बनाता है (पी। जी।, संतरे) रैखिक नहीं है। अपने आप में, प्रत्येक न्यूरॉन के खाते में लेने के लिए अलग-अलग पैरामीटर होते हैं, जो पूरे सिस्टम को बनाते हैं, यह तंत्रिका नेटवर्क है, गैर-रैखिक तरीके से वर्गीकृत।
न्यूरॉन को कैसे पता चलता है कि उसे सक्रिय होना है या नहीं? यानी, आपको कब पता चलेगा कि आपको अगली परत को जानकारी भेजनी है या नहीं? खैर, यह निर्णय निम्नलिखित समीकरण द्वारा नियंत्रित होता है:
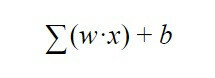
इस सूत्र का अर्थ यह निकलता है कि पिछली परत से न्यूरॉन प्राप्त होने वाले सभी भार "w" को "x" के सभी मानों से गुणा करके बनाया जाना है। इसमें जोड़ा जाता है, पूर्वाग्रह "बी" जोड़ा जाता है।
इस समीकरण का परिणाम सक्रियण समारोह में भेजा जाता है, जो केवल एक फलन है जो हमें बताता है कि, यदि इस समीकरण का परिणाम a से अधिक है निश्चित संख्या में, न्यूरॉन अगली परत को एक संकेत भेजेगा और यदि यह कम है, तो यह नहीं होगा इसे भेजने के लिए तो, इस प्रकार एक कृत्रिम न्यूरॉन निर्णय लेता है कि न्यूरॉन्स को सूचना भेजनी है या नहीं: एक आउटपुट के माध्यम से लेयर जिसे हम "y" कहेंगे, एक आउटपुट जो, बदले में, निम्न में से "x" इनपुट है न्यूरॉन।
और आप पूरे नेटवर्क को कैसे प्रशिक्षित करते हैं?
पहली बात जो की जाती है वह डेटा को पहली परत तक पहुंचाना है, जैसा कि हमने पहले टिप्पणी की है। यह परत निम्नलिखित परतों को जानकारी भेजती है, जो छिपी हुई परतें या गहरे तंत्रिका नेटवर्क हैं। प्राप्त जानकारी के आधार पर इन परतों के न्यूरॉन्स सक्रिय होंगे या नहीं। अंत में, आउटपुट लेयर हमें एक परिणाम देगा, जिसकी तुलना हम उस मूल्य से करेंगे जिसका हम इंतजार कर रहे थे कि क्या तंत्रिका नेटवर्क ने सीखा है कि सही तरीके से क्या करना है।
यदि उसने ठीक से नहीं सीखा तो हम एक और अंतःक्रिया करेंगे, अर्थात्, हम आपको फिर से जानकारी देंगे और देखेंगे कि तंत्रिका नेटवर्क कैसे व्यवहार करता है. प्राप्त परिणामों के आधार पर, "बी" मानों को समायोजित किया जाएगा, अर्थात, प्रत्येक न्यूरॉन का पूर्वाग्रह, और "डब्ल्यू", यह त्रुटि को कम करने के लिए प्रत्येक न्यूरॉन के साथ प्रत्येक कनेक्शन का वजन है। यह पता लगाने के लिए कि त्रुटि कितनी बड़ी है, हम एक अन्य समीकरण का उपयोग करने जा रहे हैं, जो निम्नलिखित है:
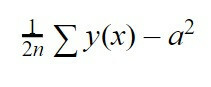
यह समीकरण मूल माध्य वर्ग त्रुटि है। हम y (x) का योग करने जा रहे हैं, जो कि वह मूल्य है जो हमारे नेटवर्क ने हमें इंटरेक्शन माइनस "ए" में दिया था, जो कि वह मूल्य है जिसकी हम उम्मीद कर रहे थे कि यह हमें वर्ग तक बढ़ाए। अंत में, हम इस राशि को 1/2n से गुणा करने जा रहे हैं, जो कि "n" हमारे तंत्रिका नेटवर्क को प्रशिक्षित करने के लिए भेजे गए इंटरैक्शन की संख्या है।
उदाहरण के लिए, मान लीजिए कि हमारे पास निम्नलिखित मान हैं

पहला कॉलम "y (x)" दर्शाता है कि हमारे नेटवर्क ने हमें उन चार इंटरैक्शन में से प्रत्येक में क्या दिया है जिनका हमने परीक्षण किया है। हमने जो मान प्राप्त किए हैं, जैसा कि देखा जा सकता है, वे दूसरे कॉलम "ए" के अनुरूप नहीं हैं, जो प्रत्येक परीक्षण किए गए इंटरैक्शन के लिए वांछित मान हैं। अंतिम कॉलम प्रत्येक इंटरैक्शन की त्रुटि का प्रतिनिधित्व करता है।
उपरोक्त सूत्र को लागू करना और यहाँ इन आंकड़ों का उपयोग करना, इस बात को ध्यान में रखते हुए कि इस स्थिति में n = 4 (4 इंटरेक्शन) हमें 3.87 का मान देता है, जो कि हमारे तंत्रिका नेटवर्क में औसत वर्ग त्रुटि है क्षण। त्रुटि को जानने के बाद, अब हमें क्या करना है, जैसा कि हमने पहले टिप्पणी की है, पूर्वाग्रह और परिवर्तन को बदलें न्यूरॉन्स में से प्रत्येक का वजन और इस इरादे से उनकी बातचीत कि इस तरह से त्रुटि है कम करना।
इस बिंदु पर, इंजीनियर और कंप्यूटर वैज्ञानिक आवेदन करते हैं एक एल्गोरिथ्म जिसे ग्रेडिएंट डिसेंट कहा जाता है जिसके साथ वे प्रत्येक कृत्रिम न्यूरॉन के पूर्वाग्रह और वजन का परीक्षण और संशोधन करने के लिए मान प्राप्त कर सकते हैं ताकि, इस तरह, भविष्यवाणी या परिणाम के निकट एक तेजी से कम त्रुटि प्राप्त हो इच्छित। यह परीक्षण का मामला है और जितनी अधिक बातचीत की जाएगी, उतना ही अधिक प्रशिक्षण होगा और उतना ही अधिक नेटवर्क सीखेगा।
एक बार तंत्रिका नेटवर्क पर्याप्त रूप से प्रशिक्षित हो जाने के बाद, यह तब होगा जब यह हमें सटीक और विश्वसनीय भविष्यवाणियां और पहचान देगा। इस बिंदु पर हमारे पास एक ऐसा नेटवर्क होने जा रहा है जिसके प्रत्येक न्यूरॉन में एक मान होगा परिभाषित वजन, एक नियंत्रित पूर्वाग्रह के साथ और एक निर्णय क्षमता के साथ जो सिस्टम बना देगा काम।
ग्रंथ सूची संदर्भ:
- पुइग, ए. [एएमपी टेक] (2017, 28 जुलाई)। तंत्रिका नेटवर्क कैसे काम करते हैं? [वीडियो फाइल]। से बरामद https://www.youtube.com/watch? v=IQMoglp-fBk&ab_channel=AMPTech
- संतोलल्ला, जे. [अपने आप को एक व्लॉग दें] (2017, 11 अप्रैल) CienciaClip Challenge - तंत्रिका नेटवर्क क्या हैं? [वीडियो फाइल]। https://www.youtube.com/watch? v=rTpr6DuY4LU&ab_channel=DateunVlog
- श्मिटहुबर, जे. (2015). "डीप लर्निंग इन न्यूरल नेटवर्क्स: एन ओवरव्यू"। तंत्रिका - तंत्र। 61: 85–117. आर्क्सिव: 1404.7828। डीओआई: 10.1016/जे.न्यूनेट.2014.09.003। पीएमआईडी 25462637। एस2सीआईडी 11715509