
Reti neurali profonde: cosa sono e come funzionano
Le reti neurali profonde sono un concetto che costituisce la principale architettura tecnologica utilizzata nei modelli di Deep Learning. Queste strutture non possono essere comprese senza comprendere l'idea generale di reti neurali artificiali, fondamentali per l'Intelligenza Artificiale.
Le reti neurali servono per mille cose: riconoscere targhe, canzoni, volti, voci, o anche i frutti della nostra cucina. Sono una tecnologia particolarmente utile e, nonostante siano diventate pratiche solo di recente, rappresenteranno il futuro dell'umanità.
Prossimo Vedremo in profondità l'idea di reti neurali artificiali e profonde, comprendendo come funzionano, come vengono allenati e come avvengono le interazioni tra i diversi neuroni che li costituiscono.
- Articolo correlato: "Cos'è la scienza cognitiva? Le sue idee di base e le fasi di sviluppo"
Cosa sono le reti neurali profonde e cosa le caratterizza?
Le reti neurali profonde lo sono una delle più importanti architetture tecnologiche utilizzate nel Deep Learning o Deep Learning
. Queste particolari reti artificiali hanno avuto una crescita vertiginosa negli ultimi anni perché costituiscono un aspetto fondamentale quando si tratta di riconoscere ogni tipo di pattern. L'Intelligenza Artificiale esiste grazie al funzionamento di queste particolari reti che, in In sostanza, arrivano ad essere una replica di come funzionano i nostri cervelli, anche se in modo tecnologico e matematica.Prima di approfondire cosa sono le reti neurali profonde, dobbiamo prima capire come funzionano le reti neurali artificiali in generale e a cosa servono. lle reti neurali sono una branca del “Machine Learning” che ha avuto un enorme impatto negli ultimi anni, aiutando programmatori e informatici a costruire cose come chatbot che, quando parliamo con loro, ci fanno pensare che stiamo parlando con veri esseri umani.
Le reti neurali artificiali sono state utilizzate anche con auto a guida autonoma, applicazioni mobili che riconoscono il nostro volto e lo trasformano in ciò che vogliamo e molti altri funzioni. La sua applicabilità è molto ampia, servendo come base della moderna Intelligenza Artificiale e avendo infiniti usi benefici per la nostra quotidianità.
reti neurali artificiali
Immaginiamo di essere nella nostra cucina e decidiamo di cercare un'arancia, operazione molto semplice.. Sappiamo identificare molto facilmente un'arancia e sappiamo anche differenziarla da altri frutti che troviamo in cucina, come banane, mele e pere. COME? Perché nel nostro cervello abbiamo molto assimilato quelle che sono le proprietà tipiche di un'arancia: la sua le sue dimensioni, la sua forma, il colore che ha, che odore ha... Questi sono tutti parametri che usiamo per trovare un arancia.
È un compito semplice per gli umani, ma... Può farlo anche un computer? La risposta è si. In linea di massima basterebbe definire quegli stessi parametri e assegnare un valore a un nodo oa qualcosa che potremmo ben chiamare “neurone artificiale”. Diremmo a quel neurone come sono le arance, indicandone le dimensioni, il peso, la forma, il colore o qualsiasi altro parametro che attribuiamo a questo frutto. Avendo queste informazioni, ci si aspetta che il neurone sappia come identificare un'arancia quando gliene viene presentata una.
Se abbiamo scelto bene i parametri, sarà facile per te distinguere tra arance e cose che non sono arance semplicemente tenendo conto di quelle caratteristiche. Quando viene presentato con un'immagine di qualsiasi frutto, quel neurone cercherà le caratteristiche associato all'arancia e decidere se inserirla nella categoria “arancia” o nella categoria “altro frutta". In termini statistici, sarebbe trovare una regione in un grafico di parametri che corrisponda a ciò che è alla ricerca di una regione che racchiuda tutti i pezzi di frutta che condividono la stessa dimensione, forma, colore, peso e aroma che il arance.
All'inizio sembra tutto molto facile da codificare, e in effetti lo è. Funziona molto bene per differenziare un'arancia da una banana o una mela, poiché hanno colori e forme diversi. Tuttavia, e se ti presentassimo un pompelmo? e un mandarino molto grande? Sono frutti che possono essere perfettamente confusi con un'arancia. Il neurone artificiale sarà in grado di distinguere da solo tra arance e pompelmi? La risposta è no, e infatti probabilmente si pensa che siano la stessa cosa.
Il problema con l'utilizzo di un solo strato di neuroni artificiali, o ciò che è lo stesso, utilizzando prima solo neuroni semplici, è questo generare confini decisionali molto imprecisi quando ti viene presentato qualcosa che ha molte caratteristiche in comune con ciò che dovresti essere in grado di riconoscere, ma in realtà non lo è. Se presentiamo qualcosa che assomiglia a un'arancia, come un pompelmo, anche se non è quel frutto, lo identificherà come tale.
Questi confini decisionali, se sono rappresentati sotto forma di un grafico, saranno sempre lineari. Utilizzando un singolo neurone artificiale, ovvero un singolo nodo che ha parametri integrati concreti, ma non possono apprendere al di là di essi, si otterranno limiti decisionali molto stretti. diffondere. Il suo limite principale è che utilizza due metodi statistici, in particolare la regressione multiclasse e regressione logistica, il che significa che in caso di dubbio include qualcosa che non è quello che ci aspettavamo che fosse. identificherà.
Se dovessimo dividere tutti i frutti in "arance" e "non arance", usando un solo neurone è chiaro che banane, pere, mele, angurie e qualsiasi frutto che non corrisponda per dimensioni, colore, forma, aroma e così via con le arance le metterei nella categoria "no". arance". Tuttavia, pompelmi e mandarini li collocherebbero nella categoria "arance", svolgendo il lavoro per il quale sono stati progettati male.
E quando si parla di arance e pompelmi si potrebbe benissimo parlare di cani e lupi, galline e galline, libri e quaderni... Tutto Queste situazioni sono casi in cui una semplice serie di "se..." ("se...") non basterebbe a distinguere chiaramente tra l'uno e l'altro. altro. È necessario un sistema più complesso, non lineare, che sia più preciso quando si tratta di differenziare i diversi elementi. Qualcosa che tenga conto che tra le somiglianze ci possono essere delle differenze. È qui che entrano in gioco le reti neurali.
Più strati, più simili al cervello umano
Le reti neurali artificiali, come suggerisce il nome, sono modelli artificiali computazionali ispirati nelle reti neurali del cervello umano, reti che di fatto imitano il funzionamento di questo organo biologico. Questo sistema si ispira al funzionamento neurale e la sua principale applicazione è il riconoscimento di modelli di tutti i tipi: identificazione facciale, riconoscimento vocale, impronte digitali, scrittura a mano, targhe automobilistiche… Il riconoscimento del modello funziona per quasi tutto..
Poiché esistono diversi neuroni, i parametri che vengono applicati sono vari e si ottiene un grado di precisione maggiore. Queste reti neurali sono sistemi che ci consentono di separare gli elementi in categorie quando il la differenza può essere sottile, separandoli in modo non lineare, cosa che altrimenti sarebbe impossibile fare maniera.
Con un singolo nodo, con un singolo neurone, ciò che viene fatto quando si gestiscono le informazioni è una regressione multiclasse. Aggiungendo più neuroni, poiché ognuno di essi ha una propria funzione di attivazione non lineare che, tradotta in un linguaggio più semplice, fa loro avere confini decisionali che sono più preciso, essendo rappresentato graficamente in una forma curva e tenendo conto di più caratteristiche quando si differenzia tra "arance" e "non arance", per continuare con quell'esempio.
La curvatura di questi confini decisionali dipenderà direttamente dal numero di strati di neuroni che aggiungiamo alla nostra rete neurale. Quegli strati di neuroni, che rendono il sistema più complesso e più preciso, sono, in effetti, reti neurali profonde. In linea di principio, più strati di reti neurali profonde abbiamo, più accurato e simile sarà il programma rispetto al cervello umano.
Insomma, le reti neurali non sono altro che un sistema intelligente che permette di prendere decisioni più precise, in modo molto simile a come lo facciamo noi esseri umani. Gli esseri umani si basano sull'esperienza, imparando dal nostro ambiente. Ad esempio, tornando al caso dell'arancia e del pompelmo, se non ne abbiamo mai visto uno, lo scambieremo perfettamente per un'arancia. Quando ne avremo preso confidenza, sarà allora che sapremo già identificarla e differenziarla dalle arance.
La prima cosa che viene fatta è dare alcuni parametri alle reti neurali in modo che sappiano com'è che vogliamo che imparino a identificare. Poi viene la fase di apprendimento o addestramento, in modo che sia sempre più accurato e abbia progressivamente un margine di errore minore. Questo è il momento in cui presenteremo alla nostra rete neurale un'arancia e altri frutti. Nella fase di addestramento verranno forniti loro casi in cui sono arancioni e casi in cui non lo sono, controllando se hanno risposto correttamente e comunicando loro la risposta corretta.
Cercheremo di fare numerosi tentativi e il più vicino possibile alla realtà.. In questo modo stiamo aiutando la rete neurale ad operare per quando arrivano casi reali e sa discriminare correttamente, nello stesso modo in cui farebbe un essere umano nella vita reale. Se la formazione è stata adeguata, avendo scelto buoni parametri di riconoscimento e si sono classificati bene, la rete neurale avrà un tasso di successo di riconoscimento del modello molto elevato. alto.
- Potresti essere interessato a: "Come funzionano i neuroni?"
Cosa sono e come funzionano esattamente?
Ora che abbiamo visto l'idea generale di cosa sono le reti neurali e capiremo più a fondo cosa sono e come questi emulatori dei neuroni del cervello umano funzionano e dove dipingono le reti neurali profonde in tutto questo processi.
Immaginiamo di avere la seguente rete neurale: abbiamo tre strati di neuroni artificiali. Diciamo che il primo strato ha 4 neuroni o nodi, il secondo 3 e l'ultimo ne ha solo 2. Questo è tutto un esempio di una rete neurale artificiale, abbastanza facile da capire.
Il primo livello è quello che riceve i dati., cioè le informazioni che possono giungere sotto forma di suono, immagine, aromi, impulsi elettrici... Questo primo layer è il layer di input, ed è incaricato di ricevere tutti i dati per poterli successivamente inviare al successivo strati. Durante l'addestramento della nostra rete neurale, questo sarà il livello con cui lavoreremo per primo, dandogli dati che useremo per vedere quanto sei bravo a fare previsioni o identificare le informazioni che ti vengono fornite dà.
Il secondo strato del nostro ipotetico modello è lo strato nascosto, che si trova proprio nel mezzo del primo e dell'ultimo strato., come se la nostra rete neurale fosse un sandwich. In questo esempio abbiamo solo un livello nascosto, ma potrebbero essercene quanti ne vogliamo. Potremmo parlare di 50, 100, 1000 o anche 50.000 strati. In sostanza, questi strati nascosti sono la parte della rete neurale che chiameremmo rete neurale profonda. Maggiore è la profondità, più complessa è la rete neurale.
Infine abbiamo il terzo livello del nostro esempio che è il livello di output. Questo strato, come indica il nome, è incaricato di ricevere informazioni dai livelli precedenti, prendere una decisione e darci una risposta o un risultato.
Nella rete neurale ogni neurone artificiale è connesso a tutti i successivi. Nel nostro esempio, dove abbiamo commentato che abbiamo tre strati di 4, 3 e 2 neuroni, i 4 dello strato di input sono connesso con il 3 del livello nascosto e il 3 del livello nascosto con il 2 dell'output, per un totale di 18 connessioni.
Tutti questi neuroni sono connessi con quelli dello strato successivo, inviando le informazioni nella direzione input->hidden->output.. Se ci fossero più livelli nascosti, parleremmo di un numero maggiore di connessioni, inviando le informazioni da livello nascosto a livello nascosto fino a raggiungere il livello di output. Il livello di output, una volta ricevute le informazioni, ciò che farà è darci un risultato basato sulle informazioni che ha ricevuto e sul suo modo di elaborarle.
Quando addestriamo il nostro algoritmo, cioè la nostra rete neurale, questo processo che abbiamo appena spiegato verrà eseguito molte volte. Forniremo alcuni dati alla rete, vedremo cosa ci dà il risultato e lo analizzeremo e lo confronteremo con quello che ci aspettavamo che il risultato ci desse. Se c'è una grande differenza tra ciò che ci si aspetta e ciò che si ottiene, significa che c'è un alto margine di errore e che, quindi, è necessario apportare alcune modifiche.
Come funzionano i neuroni artificiali?
Ora capiremo il funzionamento individuale dei neuroni che lavorano all'interno di una rete neurale. Il neurone riceve un input di informazioni dal neurone precedente. Diciamo che questo neurone riceve tre input informativi, ciascuno proveniente dai tre neuroni dello strato precedente. A sua volta, questo neurone genera degli output, in questo caso diciamo che è connesso solo a un neurone dello strato successivo.
Ogni connessione che questo neurone ha con i tre neuroni dello strato precedente porta un valore "x", che è il valore che il neurone precedente ci sta inviando.; e ha anche un valore "w", che è il peso di questa connessione. Il peso è un valore che ci aiuta a dare più importanza a una connessione rispetto ad altre. Insomma, ogni connessione con i neuroni precedenti ha un valore “x” e un valore “w”, che vengono moltiplicati (x·w).
Avremo anche un valore chiamato "bias" o bias rappresentato con "b" che è il numero di errore che incoraggia certi neuroni ad attivarsi più facilmente di altri. Inoltre, abbiamo una funzione di attivazione all'interno del neurone, che è ciò che rende il suo grado di classificazione dei diversi elementi (p. g., arance) non è lineare. Di per sé, ogni neurone ha parametri diversi da tenere in considerazione, il che rende l'intero sistema, questa è la rete neurale, classificata in modo non lineare.
Come fa il neurone a sapere se deve attivarsi o meno? cioè, quando sai se devi inviare informazioni al livello successivo? Bene, questa decisione è governata dalla seguente equazione:
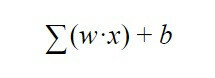
Questa formula viene a significare che deve essere fatta la somma di tutti i pesi "w" moltiplicati per tutti i valori di "x" che il neurone sta ricevendo dallo strato precedente. A questo si aggiunge il pregiudizio "b".
Il risultato di questa equazione viene inviato a una funzione di attivazione, che è semplicemente una funzione che ci dice che, se il risultato di questa equazione è maggiore di a certo numero, il neurone invierà un segnale allo strato successivo e, se è inferiore, non lo farà per inviarlo Quindi, questo è il modo in cui un neurone artificiale decide se inviare o meno informazioni ai neuroni come segue: layer mediante un output che chiameremo "y", output che, a sua volta, è l'input "x" del seguente neurone.
E come si addestra un'intera rete?
La prima cosa da fare è consegnare i dati al primo livello, come abbiamo commentato in precedenza. Questo livello invierà informazioni ai livelli successivi, che sono i livelli nascosti o la rete neurale profonda. I neuroni di questi strati si attiveranno o meno a seconda delle informazioni ricevute. Infine, il livello di output ci darà un risultato, che confronteremo con il valore che stavamo aspettando per vedere se la rete neurale ha imparato cosa fare correttamente.
Se non ha imparato bene, eseguiremo un'altra interazione, ovvero ti presenteremo nuovamente le informazioni e vedremo come si comporta la rete neurale. A seconda dei risultati ottenuti, verranno regolati i valori "b", ovvero il bias di ciascun neurone, e "w", questo è il peso di ciascuna connessione con ciascun neurone per ridurre l'errore. Per scoprire quanto è grande questo errore, useremo un'altra equazione, che è la seguente:
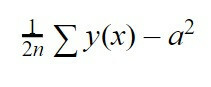
Questa equazione è la radice dell'errore quadratico medio. Faremo la somma di y (x) che è il valore che la nostra rete ci ha dato nell'interazione meno “a”, che è il valore che ci aspettavamo che ci desse, elevato al quadrato. Infine, moltiplichiamo questa somma per 1/2n, essendo quella "n" il numero di interazioni che abbiamo inviato per addestrare la nostra rete neurale.
Ad esempio, supponiamo di avere i seguenti valori

La prima colonna “y (x)” rappresenta ciò che la nostra rete ci ha dato in ciascuna delle quattro interazioni che l'abbiamo testata. I valori che abbiamo ottenuto, come si vede, non corrispondono a quelli della seconda colonna “a”, che sono i valori desiderati per ognuna delle interazioni testate. L'ultima colonna rappresenta l'errore di ciascuna interazione.
Applicando la suddetta formula e utilizzando qui questi dati, tenendo presente che in questo caso n = 4 (4 interazioni) ci dà un valore di 3,87, che è l'errore quadratico medio che la nostra rete neurale ha in queste momenti. Conoscendo l'errore, quello che dobbiamo fare ora è, come abbiamo già commentato, cambiare il bias e il pesi di ciascuno dei neuroni e delle loro interazioni con l'intenzione che in questo modo l'errore sia ridurre.
A questo punto si applicano ingegneri e informatici un algoritmo chiamato discesa del gradiente con cui possono ottenere valori per testare e modificare il bias e il peso di ogni neurone artificiale in modo che, in questo modo, si ottenga un errore sempre più basso, avvicinandosi alla previsione o al risultato ricercato. È una questione di test e più interazioni si fanno, più formazione ci sarà e più la rete imparerà.
Una volta che la rete neurale sarà adeguatamente addestrata, sarà quando ci fornirà previsioni e identificazioni accurate e affidabili. A questo punto avremo una rete che avrà in ognuno dei suoi neuroni un valore di peso definito, con un bias controllato e con una capacità decisionale che farà sistema lavoro.
Riferimenti bibliografici:
- Puig, A. [AMP Tech] (2017, 28 luglio). Come funzionano le reti neurali? [File video]. Recuperato da https://www.youtube.com/watch? v=IQMoglp-fBk&ab_channel=AMPTech
- Santaolalla, J. [Regalati un Vlog] (2017, 11 aprile) CienciaClip Challenge - Cosa sono le reti neurali? [File video]. https://www.youtube.com/watch? v=rTpr6DuY4LU&ab_channel=DateunVlog
- Schmidhuber, J. (2015). "Deep Learning nelle reti neurali: una panoramica". Reti neurali. 61: 85–117. arXiv: 1404.7828. doi: 10.1016/j.neunet.2014.09.003. PMID 25462637. S2CID 11715509


