
Diepe neurale netwerken: wat ze zijn en hoe ze werken
Diepe neurale netwerken zijn een concept dat de belangrijkste technologische architectuur vormt die wordt gebruikt in Deep Learning-modellen. Deze structuren kunnen niet worden begrepen zonder het algemene idee van kunstmatige neurale netwerken te begrijpen, fundamenteel voor kunstmatige intelligentie.
Neurale netwerken worden voor duizend dingen gebruikt: het herkennen van kentekenplaten, liedjes, gezichten, stemmen of zelfs het fruit in onze keuken. Ze zijn een bijzonder nuttige technologie en ondanks het feit dat ze pas sinds kort praktisch zijn geworden, zullen ze de toekomst van de mensheid worden.
Volgende We gaan dieper in op het idee van kunstmatige neurale netwerken en diep, begrijpen hoe ze werken, hoe ze worden getraind en hoe de interacties tussen de verschillende neuronen waaruit ze bestaan, plaatsvinden.
- Gerelateerd artikel: "Wat is cognitieve wetenschap? De basisideeën en ontwikkelingsfasen"
Wat zijn diepe neurale netwerken en wat kenmerkt ze?
Diepe neurale netwerken zijn dat wel
een van de belangrijkste technologische architecturen die worden gebruikt bij Deep Learning of Deep Learning. Deze bijzondere kunstmatige netwerken hebben de afgelopen jaren een duizelingwekkende groei doorgemaakt omdat ze een fundamenteel aspect vormen bij het herkennen van allerlei patronen. Kunstmatige intelligentie bestaat dankzij de werking van deze specifieke netwerken die, in In wezen worden ze een replica van hoe onze hersenen werken, zij het op een technologische en wiskunde.Voordat we verder ingaan op wat diepe neurale netwerken zijn, moeten we eerst begrijpen hoe kunstmatige neurale netwerken in het algemeen werken en waarvoor ze dienen. Lneurale netwerken zijn een tak van "Machine Learning" die de afgelopen jaren een enorme impact hebben gehad, programmeurs en computerwetenschappers helpen dingen zoals chatbots te bouwen die, als we met ze praten, ons doen denken dat we met echte mensen praten.
Kunstmatige neurale netwerken zijn ook gebruikt bij zelfrijdende auto's, mobiele applicaties die ons gezicht herkennen en transformeren in wat we willen en nog veel meer functies. De toepasbaarheid ervan is zeer uitgebreid, dient als basis van moderne kunstmatige intelligentie en heeft eindeloos veel nuttige toepassingen voor ons dagelijks leven.
kunstmatige neurale netwerken
Laten we ons voorstellen dat we in onze keuken zijn en besluiten om op zoek te gaan naar een sinaasappel, een heel eenvoudige taak.. We weten hoe we een sinaasappel heel gemakkelijk kunnen herkennen en we weten ook hoe we hem kunnen onderscheiden van ander fruit dat we in de keuken vinden, zoals bananen, appels en peren. Als? Omdat we in onze hersenen heel goed hebben geassimileerd wat de typische eigenschappen van een sinaasappel zijn: zijn de grootte, de vorm, de kleur die het heeft, hoe het ruikt... Dit zijn allemaal parameters die we gebruiken om een oranje.
Het is een eenvoudige taak voor mensen, maar... Kan een computer dat ook? Het antwoord is ja. In principe zou het voldoende zijn om diezelfde parameters te definiëren en een waarde toe te kennen aan een knooppunt of iets dat we een "kunstmatig neuron" zouden kunnen noemen. We zouden dat neuron vertellen hoe sinaasappels zijn, door hun grootte, gewicht, vorm, kleur of enige andere parameter die we aan deze vrucht toeschrijven, aan te geven. Met deze informatie wordt verwacht dat het neuron weet hoe het een sinaasappel moet identificeren wanneer het er een krijgt aangeboden.
Als we de parameters goed hebben gekozen, zal het voor u gemakkelijk zijn om onderscheid te maken tussen sinaasappels en dingen die geen sinaasappels zijn, simpelweg door rekening te houden met die kenmerken. Wanneer het een afbeelding van een vrucht krijgt, zal dat neuron naar de kenmerken zoeken geassocieerd met de sinaasappel en beslis of u deze wilt opnemen in de categorie "sinaasappel" of in de categorie "anders". fruit". In statistische termen zou het zijn om een regio in een parametergrafiek te vinden die overeenkomt met wat er is op zoek naar een regio die alle stukken fruit zou omvatten die dezelfde grootte, vorm, kleur, gewicht en aroma delen die de sinaasappels.
In eerste instantie klinkt dit allemaal heel eenvoudig te coderen, en dat is het ook. Het werkt heel goed om een sinaasappel te onderscheiden van een banaan of een appel, omdat ze verschillende kleuren en vormen hebben. Maar wat als we u een grapefruit zouden aanbieden? en een hele grote mandarijn? Het zijn vruchten die perfect verward kunnen worden met een sinaasappel. Zal het kunstmatige neuron zelf onderscheid kunnen maken tussen sinaasappels en grapefruits? Het antwoord is nee, en in feite wordt waarschijnlijk gedacht dat ze hetzelfde zijn.
Het probleem met het gebruik van slechts één laag kunstmatige neuronen, of wat hetzelfde is, alleen eerst eenvoudige neuronen gebruiken, is dat zeer onnauwkeurige beslissingsgrenzen genereren wanneer u iets wordt gepresenteerd dat veel kenmerken gemeen heeft met wat u zou moeten kunnen herkennen, maar dat is het in werkelijkheid niet. Als we iets presenteren dat op een sinaasappel lijkt, zoals een grapefruit, zelfs als het niet die vrucht is, zal het het als zodanig identificeren.
Deze beslissingsgrenzen zullen, als ze worden weergegeven in de vorm van een grafiek, altijd lineair zijn. Een enkel kunstmatig neuron gebruiken, dat wil zeggen een enkel knooppunt met geïntegreerde parameters concreet zijn, maar niet verder kunnen leren, zullen zeer nauwe beslissingsgrenzen worden verkregen. diffuus. De belangrijkste beperking is dat het twee statistische methoden gebruikt, met name multiclass-regressie en logistische regressie, wat betekent dat het bij twijfel iets bevat dat niet is wat we ervan verwachtten. zal identificeren.
Als we alle vruchten zouden verdelen in "sinaasappels" en "niet-sinaasappels", met slechts één neuron, dan is het duidelijk dat bananen, peren, appels, watermeloenen en al het fruit dat qua grootte, kleur, vorm, aroma enzovoort niet overeenkomt met sinaasappels, zou ik in de categorie "nee" plaatsen. sinaasappelen". Grapefruits en mandarijnen zouden ze echter in de categorie "sinaasappels" plaatsen, omdat ze het werk doen waarvoor ze slecht zijn ontworpen.
En als we het over sinaasappels en grapefruits hebben, kunnen we het heel goed hebben over honden en wolven, kippen en kippen, boeken en notitieboekjes... Allemaal Deze situaties zijn gevallen waarin een simpele reeks van "als..." ("als...") niet voldoende zou zijn om duidelijk onderscheid te maken tussen de een en de ander. ander. Er is een complexer, niet-lineair systeem nodig, dat nauwkeuriger is als het gaat om het differentiëren tussen verschillende elementen. Iets dat er rekening mee houdt dat er tussen de overeenkomsten verschillen kunnen zitten. Dit is waar neurale netwerken binnenkomen.
Meer lagen, meer vergelijkbaar met het menselijk brein
Kunstmatige neurale netwerken, zoals hun naam al doet vermoeden, zijn computationele kunstmatige modellen geïnspireerd door in de neurale netwerken van het menselijk brein, netwerken die in feite de werking van dit orgaan nabootsen biologisch. Dit systeem is geïnspireerd op het neuraal functioneren en de belangrijkste toepassing is de herkenning van allerlei soorten patronen: gezichtsherkenning, stemherkenning, vingerafdruk, handschrift, kenteken plaat… Patroonherkenning werkt voor bijna alles..
Omdat er verschillende neuronen zijn, zijn de parameters die worden toegepast verschillend en wordt een hogere mate van precisie verkregen. Deze neurale netwerken zijn systemen waarmee we items in categorieën kunnen scheiden wanneer de verschil kan subtiel zijn, ze op een niet-lineaire manier van elkaar scheiden, iets dat anders onmogelijk zou zijn manier.
Met een enkel knooppunt, met een enkel neuron, is wat er wordt gedaan bij het verwerken van de informatie een regressie met meerdere klassen. Door meer neuronen toe te voegen, aangezien elk van hen zijn eigen niet-lineaire activeringsfunctie heeft die, vertaald in eenvoudiger taal, ervoor zorgt dat ze beslissingsgrenzen hebben die preciezer, grafisch weergegeven in een gebogen vorm en rekening houdend met meer kenmerken bij het maken van onderscheid tussen "sinaasappels" en "geen sinaasappels", om met dat voorbeeld verder te gaan.
De kromming van deze beslissingsgrenzen hangt rechtstreeks af van het aantal lagen neuronen dat we aan ons neurale netwerk toevoegen. Die lagen van neuronen, die het systeem complexer en nauwkeuriger maken, zijn in feite diepe neurale netwerken. In principe geldt: hoe meer lagen van diepe neurale netwerken we hebben, hoe nauwkeuriger en vergelijkbaarer het programma zal zijn in vergelijking met het menselijk brein.
Kortom, neurale netwerken zijn niets meer dan een intelligent systeem waarmee nauwkeurigere beslissingen kunnen worden genomen, op een manier die sterk lijkt op hoe wij mensen dat doen. Mensen zijn gebaseerd op ervaring, leren van onze omgeving. Als we bijvoorbeeld teruggaan naar het geval van sinaasappel en grapefruit, als we er nog nooit een hebben gezien, zullen we het perfect verwarren met een sinaasappel. Als we er vertrouwd mee zijn geraakt, zullen we al weten hoe we het moeten identificeren en onderscheiden van sinaasappels.
Het eerste dat wordt gedaan, is enkele parameters aan de neurale netwerken geven, zodat ze weten hoe het is dat we het willen leren identificeren. Dan komt de leer- of trainingsfase, zodat deze steeds nauwkeuriger wordt en geleidelijk een kleinere foutmarge heeft. Dit is het moment waarop we ons neurale netwerk zouden presenteren met een sinaasappel en ander fruit. In de trainingsfase krijgen ze gevallen waarin ze oranje zijn en gevallen waarin ze niet oranje zijn, waarbij ze kijken of ze het juiste antwoord hebben gegeven en het juiste antwoord geven.
We zullen proberen talloze pogingen te doen en zo dicht mogelijk bij de realiteit te komen.. Op deze manier helpen we het neurale netwerk te functioneren wanneer er echte gevallen aankomen en het weet hoe het op de juiste manier onderscheid moet maken, net zoals een mens dat in het echte leven zou doen. Als de training adequaat is geweest, goede herkenningsparameters hebben gekozen en goed zijn geclassificeerd, zal het neurale netwerk een zeer hoog succespercentage voor patroonherkenning hebben. hoog.
- Mogelijk bent u geïnteresseerd in: "Hoe werken neuronen?"
Wat zijn het en hoe werken ze precies?
Nu we het algemene idee hebben gezien van wat neurale netwerken zijn, gaan we beter begrijpen wat ze zijn en hoe deze emulators van de neuronen van het menselijk brein werken en waar schilderen diepe neurale netwerken in dit alles proces.
Laten we ons voorstellen dat we het volgende neurale netwerk hebben: we hebben drie lagen kunstmatige neuronen. Laten we zeggen dat de eerste laag 4 neuronen of knooppunten heeft, de tweede 3 en de laatste slechts 2. Dit is allemaal een voorbeeld van een kunstmatig neuraal netwerk, vrij gemakkelijk te begrijpen.
De eerste laag is degene die de gegevens ontvangt., dat wil zeggen, de informatie die mogelijk komt in de vorm van geluid, beeld, aroma's, elektrische impulsen... Deze eerste laag is de invoerlaag en is verantwoordelijk voor het ontvangen van alle gegevens om deze later naar het volgende te kunnen sturen lagen. Tijdens de training van ons neurale netwerk zal dit de laag zijn waarmee we als eerste gaan werken, geven gegevens die we zullen gebruiken om te zien hoe goed u bent in het doen van voorspellingen of het identificeren van de informatie die u krijgt geeft.
De tweede laag van ons hypothetische model is de verborgen laag, die precies in het midden van de eerste en laatste laag zit., alsof ons neurale netwerk een sandwich is. In dit voorbeeld hebben we maar één verborgen laag, maar er kunnen er zoveel zijn als we willen. We zouden kunnen praten over 50, 100, 1000 of zelfs 50.000 lagen. In wezen zijn deze verborgen lagen het deel van het neurale netwerk dat we het diepe neurale netwerk zouden noemen. Hoe groter de diepte, hoe complexer het neurale netwerk.
Eindelijk hebben we de derde laag van ons voorbeeld, de uitvoerlaag. Deze laag, zoals de naam aangeeft, is verantwoordelijk voor het ontvangen van informatie uit de vorige lagen, het nemen van een beslissing en het geven van een antwoord of resultaat.
In het neurale netwerk is elk kunstmatig neuron verbonden met alle volgende. In ons voorbeeld, waar we hebben opgemerkt dat we drie lagen van 4, 3 en 2 neuronen hebben, zijn de 4 van de invoerlaag verbonden met de 3 van de verborgen laag, en de 3 van de verborgen laag met de 2 van de uitvoer, wat ons een totaal van 18 geeft verbindingen.
Al deze neuronen zijn verbonden met die van de volgende laag en sturen de informatie in de invoer->verborgen->uitvoerrichting.. Als er meer verborgen lagen waren, zouden we het hebben over een groter aantal verbindingen, waarbij de informatie van verborgen laag naar verborgen laag wordt verzonden totdat deze de uitvoerlaag bereikt. Zodra de uitvoerlaag de informatie heeft ontvangen, geeft het ons een resultaat op basis van de informatie die het heeft ontvangen en de manier waarop het wordt verwerkt.
Wanneer we ons algoritme, dat wil zeggen ons neurale netwerk, trainen, zal dit proces dat we zojuist hebben uitgelegd vele malen worden uitgevoerd. We gaan wat gegevens aan het netwerk leveren, we gaan kijken wat het resultaat ons oplevert en we gaan het analyseren en vergelijken met wat we verwachtten dat het resultaat ons zou geven. Als er een groot verschil is tussen wat wordt verwacht en wat wordt verkregen, betekent dit dat er een grote foutmarge is en dat het daarom nodig is om enkele wijzigingen aan te brengen.
Hoe werken kunstmatige neuronen?
Nu gaan we de individuele werking begrijpen van de neuronen die binnen een neuraal netwerk werken. Het neuron ontvangt informatie van het vorige neuron. Laten we zeggen dat dit neuron drie informatie-invoer ontvangt, elk afkomstig van de drie neuronen van de vorige laag. Dit neuron genereert op zijn beurt output, laten we in dit geval zeggen dat het alleen is verbonden met een neuron van de volgende laag.
Elke verbinding die dit neuron heeft met de drie neuronen van de vorige laag brengt een "x"-waarde met zich mee, wat de waarde is die het vorige neuron ons stuurt.; en het heeft ook een waarde "w", wat het gewicht is van deze verbinding. Gewicht is een waarde die ons helpt meer belang te hechten aan de ene verbinding dan aan de andere. Kortom, elke verbinding met de vorige neuronen heeft een "x" en een "w" waarde, die vermenigvuldigd worden (x·w).
We gaan ook hebben een waarde genaamd "bias" of bias weergegeven met "b", wat het aantal fouten is dat bepaalde neuronen aanmoedigt om gemakkelijker te activeren dan andere. Bovendien hebben we een activeringsfunctie binnen het neuron, waardoor de mate van classificatie van verschillende elementen (p. sinaasappels) is niet lineair. Op zichzelf heeft elk neuron verschillende parameters waarmee rekening moet worden gehouden, waardoor het hele systeem, dit is het neurale netwerk, op een niet-lineaire manier classificeert.
Hoe weet het neuron of het moet activeren of niet? dat wil zeggen, wanneer weet je of je informatie naar de volgende laag moet sturen? Welnu, deze beslissing wordt bepaald door de volgende vergelijking:
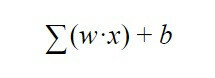
Deze formule komt erop neer dat de som van alle gewichten "w" vermenigvuldigd met alle waarden van "x" die het neuron ontvangt van de vorige laag moet worden gemaakt. Daarbij komt nog de bias "b".
Het resultaat van deze vergelijking wordt naar een activeringsfunctie gestuurd, wat gewoon een functie is die ons vertelt dat, als het resultaat van deze vergelijking groter is dan a bepaald aantal, zal het neuron een signaal naar de volgende laag sturen en, als het minder is, dan niet om het te sturen Dit is dus hoe een kunstmatig neuron als volgt beslist om al dan niet informatie naar de neuronen te sturen: laag door middel van een uitvoer die we "y" zullen noemen, een uitvoer die op zijn beurt de invoer "x" is van het volgende neuron.
En hoe train je een heel netwerk?
Het eerste dat wordt gedaan, is het leveren van gegevens aan de eerste laag, zoals we eerder hebben opgemerkt. Deze laag stuurt informatie naar de volgende lagen, de verborgen lagen of het diepe neurale netwerk. De neuronen van deze lagen worden al dan niet geactiveerd, afhankelijk van de ontvangen informatie. Ten slotte geeft de uitvoerlaag ons een resultaat, dat we zullen vergelijken met de waarde waarop we zaten te wachten om te zien of het neurale netwerk heeft geleerd wat het correct moet doen.
Als hij niet goed heeft geleerd, zullen we een andere interactie uitvoeren, namelijk we zullen u opnieuw informatie presenteren en zien hoe het neurale netwerk zich gedraagt. Afhankelijk van de verkregen resultaten, worden de "b" -waarden aangepast, dat wil zeggen de bias van elk neuron, en de "w", dit is het gewicht van elke verbinding met elk neuron om de fout te verminderen. Om erachter te komen hoe groot die fout is, gaan we een andere vergelijking gebruiken, namelijk de volgende:
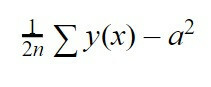
Deze vergelijking is de root mean square error. We gaan de som van y (x) doen, wat de waarde is die ons netwerk ons gaf in de interactie minus "a", wat de waarde is die we verwachtten dat het ons zou geven, verheven tot het kwadraat. Ten slotte gaan we deze som vermenigvuldigen met 1/2n, zijnde dat "n" het aantal interacties is dat we hebben verzonden om ons neurale netwerk te trainen.
Stel bijvoorbeeld dat we de volgende waarden hebben

De eerste kolom "y (x)" geeft weer wat ons netwerk ons heeft gegeven in elk van de vier interacties die we hebben getest. De waarden die we hebben verkregen, zoals te zien is, komen niet overeen met die van de tweede kolom "a", wat de gewenste waarden zijn voor elk van de geteste interacties. De laatste kolom vertegenwoordigt de fout van elke interactie.
Door de bovengenoemde formule toe te passen en deze gegevens hier te gebruiken, rekening houdend met het feit dat in dit geval n = 4 (4 interacties) geeft ons een waarde van 3,87, wat de gemiddelde kwadratische fout is die ons neurale netwerk hierin heeft momenten. Nu we de fout kennen, moeten we nu, zoals we eerder hebben opgemerkt, de vooringenomenheid en de gewichten van elk van de neuronen en hun interacties met de bedoeling dat op deze manier de fout is verminderen.
Op dit punt zijn ingenieurs en computerwetenschappers van toepassing een algoritme dat gradiëntafdaling wordt genoemd waarmee ze waarden kunnen verkrijgen om de bias en het gewicht van elk kunstmatig neuron te testen en aan te passen zodat op deze manier een steeds kleinere fout wordt verkregen die de voorspelling of het resultaat benadert gewild. Het is een kwestie van testen en hoe meer interacties er zijn, hoe meer training er zal zijn en hoe meer het netwerk zal leren.
Zodra het neurale netwerk voldoende is getraind, zal het ons nauwkeurige en betrouwbare voorspellingen en identificaties geven. Op dit punt krijgen we een netwerk dat in elk van zijn neuronen een waarde heeft van gedefinieerd gewicht, met een gecontroleerde bias en met een beslissingscapaciteit die het systeem zal maken werk.
Bibliografische referenties:
- Puig, A. [AMP Tech] (2017, 28 juli). Hoe werken neurale netwerken? [Video bestand]. Hersteld van https://www.youtube.com/watch? v=IQMoglp-fBk&ab_channel=AMPTech
- Santaolalla, J. [Geef jezelf een vlog] (2017, 11 april) CienciaClip Challenge - Wat zijn neurale netwerken? [Video bestand]. https://www.youtube.com/watch? v=rTpr6DuY4LU&ab_channel=DateunVlog
- Schmidhuber, J. (2015). "Deep Learning in neurale netwerken: een overzicht". Neurale netwerken. 61: 85–117. arXiv: 1404.7828. doi: 10.1016/j.neunet.2014.09.003. PMID 25462637. S2CID 11715509