
Réseaux de neurones profonds: qu'est-ce que c'est et comment ils fonctionnent ?
Les réseaux de neurones profonds sont un concept qui constitue la principale architecture technologique utilisée dans les modèles de Deep Learning. Ces structures ne peuvent être comprises sans comprendre l'idée générale de réseaux de neurones artificiels, fondamentale pour l'Intelligence Artificielle.
Les réseaux de neurones servent à mille choses: reconnaître les plaques d'immatriculation, les chansons, les visages, les voix ou même les fruits de notre cuisine. Il s'agit d'une technologie particulièrement utile et, malgré le fait qu'elle ne soit devenue pratique que récemment, elle sera l'avenir de l'humanité.
Ensuite Nous allons voir en profondeur l'idée des réseaux de neurones artificiels et profonds, comprendre comment ils fonctionnent, comment ils sont entraînés et comment se produisent les interactions entre les différents neurones qui les constituent.
- Article associé: « Qu'est-ce que la science cognitive? Ses idées de base et ses phases de développement"
Que sont les réseaux de neurones profonds et qu'est-ce qui les caractérise ?
Les réseaux de neurones profonds sont une des architectures technologiques les plus importantes utilisées en Deep Learning ou Deep Learning. Ces réseaux artificiels particuliers ont connu une croissance vertigineuse ces dernières années car ils constituent un aspect fondamental lorsqu'il s'agit de reconnaître toutes sortes de modèles. L'Intelligence Artificielle existe grâce au fonctionnement de ces réseaux particuliers qui, en Essentiellement, ils deviennent une réplique du fonctionnement de notre cerveau, bien que d'un point de vue technologique et mathématiques.
Avant d'aller plus loin dans ce que sont les réseaux de neurones profonds, nous devons d'abord comprendre comment fonctionnent les réseaux de neurones artificiels en général et à quoi ils servent. Lles réseaux de neurones sont une branche du "Machine Learning" qui a eu un impact énorme ces dernières années, aidant les programmeurs et les informaticiens à créer des choses comme des chatbots qui, lorsque nous leur parlons, nous font penser que nous parlons à de vrais êtres humains.
Les réseaux de neurones artificiels ont également été utilisés avec des voitures autonomes, des applications mobiles qui reconnaissent notre visage et le transforment en ce que nous voulons et bien d'autres les fonctions. Son applicabilité est très étendue, servant de base à l'intelligence artificielle moderne et ayant des utilisations bénéfiques infinies pour notre quotidien.
réseaux de neurones artificiels
Imaginons que nous sommes dans notre cuisine et que nous décidons de chercher une orange, une tâche très simple.. On sait identifier très facilement une orange et on sait aussi la différencier des autres fruits que l'on trouve en cuisine, comme les bananes, les pommes et les poires. Comme? Parce que dans notre cerveau nous avons très bien assimilé quelles sont les propriétés typiques d'une orange: son sa taille, sa forme, sa couleur, son odeur... Ce sont autant de paramètres que nous utilisons pour trouver un Orange.
C'est une tâche simple pour les humains, mais... Un ordinateur peut-il le faire aussi? La réponse est oui. En principe, il suffirait de définir ces mêmes paramètres et d'attribuer une valeur à un nœud ou quelque chose que l'on pourrait bien appeler un « neurone artificiel ». Nous dirions à ce neurone à quoi ressemblent les oranges, en indiquant leur taille, leur poids, leur forme, leur couleur ou tout autre paramètre que nous attribuons à ce fruit. Ayant cette information, on s'attend à ce que le neurone sache identifier une orange lorsqu'on lui en présente une.
Si nous avons bien choisi les paramètres, il vous sera facile de différencier les oranges des choses qui ne sont pas des oranges simplement en tenant compte de ces caractéristiques. Lorsqu'il est présenté avec une image de n'importe quel fruit, ce neurone recherchera les caractéristiques associé à l'orange et décider de l'inclure dans la catégorie « orange » ou dans la catégorie « autre fruit". En termes statistiques, il s'agirait de trouver une région dans un graphique de paramètres qui correspond à ce qui est à la recherche d'une région qui engloberait tous les morceaux de fruits qui partagent la même taille, forme, couleur, poids et arôme que le des oranges.
Au début, tout cela semble très facile à coder, et en fait ça l'est. Cela fonctionne très bien pour différencier une orange d'une banane ou d'une pomme, car elles ont des couleurs et des formes différentes. Et si on vous offrait un pamplemousse? et une très grosse mandarine? Ce sont des fruits qui peuvent parfaitement être confondus avec une orange. Le neurone artificiel pourra-t-il à lui seul différencier les oranges des pamplemousses? La réponse est non, et en fait, on pense probablement qu'ils sont les mêmes.
Le problème avec l'utilisation d'une seule couche de neurones artificiels, ou ce qui revient au même, en n'utilisant d'abord que des neurones simples, c'est que générer des limites de décision très imprécises lorsque vous êtes confronté à quelque chose qui a de nombreuses caractéristiques en commun avec ce que vous devriez être capable de reconnaître, mais en réalité ce n'est pas le cas. Si nous présentons quelque chose qui ressemble à une orange, comme un pamplemousse, même si ce n'est pas ce fruit, il l'identifiera comme tel.
Ces frontières de décision, si elles sont représentées sous forme de graphe, seront toujours linéaires. Utiliser un seul neurone artificiel, c'est-à-dire un seul nœud qui a des paramètres intégrés concrets, mais ne peuvent pas apprendre au-delà, des limites de décision très étroites seront obtenues. diffuser. Sa principale limitation est qu'il utilise deux méthodes statistiques, à savoir la régression multiclasse et régression logistique, ce qui signifie qu'en cas de doute, il inclut quelque chose qui n'est pas ce que nous attendions qu'il soit. identifiera.
Si nous devions diviser tous les fruits en « oranges » et « non oranges », en utilisant un seul neurone, il est clair que les bananes, les poires, pommes, pastèques et tout fruit dont la taille, la couleur, la forme, l'arôme, etc. ne correspondent pas aux oranges, je les mettrais dans la catégorie "non". des oranges". Cependant, les pamplemousses et les mandarines les placeraient dans la catégorie des "oranges", faisant le travail pour lequel ils ont été mal conçus.
Et quand on parle d'oranges et de pamplemousses on pourrait bien parler de chiens et de loups, de poules et de poulets, de livres et de cahiers... Tous Ces situations sont des cas où une simple série de "si..." ("si...") ne suffirait pas à bien distinguer l'un de l'autre. autre. Un système non linéaire plus complexe est nécessaire, qui est plus précis lorsqu'il s'agit de différencier les différents éléments. Quelque chose qui tient compte du fait qu'entre les similitudes, il peut y avoir des différences. C'est là qu'interviennent les réseaux de neurones.
Plus de couches, plus similaires au cerveau humain
Les réseaux de neurones artificiels, comme leur nom l'indique, sont des modèles artificiels computationnels inspirés de dans les réseaux de neurones du cerveau humain, réseaux qui imitent en fait le fonctionnement de cet organe biologique. Ce système s'inspire du fonctionnement neuronal et sa principale application est la reconnaissance de motifs de toutes sortes: identification faciale, reconnaissance vocale, empreintes digitales, écriture manuscrite, plaques d'immatriculation… La reconnaissance de formes fonctionne pour presque tout..
Comme il y a différents neurones, les paramètres appliqués sont variés et une plus grande précision est obtenue. Ces réseaux de neurones sont des systèmes qui nous permettent de séparer les éléments en catégories lorsque le la différence peut être subtile, les séparant de manière non linéaire, ce qui serait impossible à faire autrement manière.
Avec un seul nœud, avec un seul neurone, ce qui est fait lors du traitement de l'information est une régression multiclasse. En ajoutant plus de neurones, car chacun d'eux a sa propre fonction d'activation non linéaire qui, traduite en langage plus simple, leur fait avoir des frontières de décision qui sont plus précis, étant représenté graphiquement sous une forme courbe et prenant en compte plus de caractéristiques lors de la différenciation entre "oranges" et "pas oranges", pour continuer avec cet exemple.
La courbure de ces frontières de décision dépendra directement du nombre de couches de neurones que nous ajouterons à notre réseau de neurones. Ces couches de neurones, qui rendent le système plus complexe et plus précis, sont en fait des réseaux de neurones profonds. En principe, plus nous avons de couches de réseaux de neurones profonds, plus le programme sera précis et similaire au cerveau humain.
En bref, les réseaux de neurones ne sont rien de plus que un système intelligent qui permet de prendre des décisions plus précises, d'une manière très similaire à la façon dont nous, les êtres humains, le faisons. Les êtres humains sont basés sur l'expérience, en apprenant de notre environnement. Par exemple, pour en revenir au cas de l'orange et du pamplemousse, si nous n'en avons jamais vu, nous le confondrons parfaitement avec une orange. Quand nous nous serons familiarisés avec elle, ce sera alors que nous saurons déjà l'identifier et la différencier des oranges.
La première chose à faire est de donner des paramètres aux réseaux de neurones pour qu'ils sachent ce que nous voulons qu'ils apprennent à identifier. Vient ensuite la phase d'apprentissage ou d'apprentissage, afin qu'il soit de plus en plus précis et présente progressivement une marge d'erreur plus faible. C'est le moment où nous présenterions notre réseau de neurones avec une orange et d'autres fruits. Dans la phase de formation, ils recevront des cas dans lesquels ils sont orange et des cas dans lesquels ils ne sont pas orange, en regardant pour voir s'ils ont obtenu leur bonne réponse et en leur disant la bonne réponse.
Nous essaierons de faire de nombreuses tentatives et au plus proche de la réalité.. De cette façon, nous aidons le réseau de neurones à fonctionner lorsque des cas réels arrivent et il sait comment discriminer correctement, de la même manière qu'un être humain le ferait dans la vraie vie. Si la formation a été adéquate, en ayant choisi de bons paramètres de reconnaissance et ont bien classé, le réseau de neurones va avoir un taux de réussite de reconnaissance de formes très élevé. haut.
- Vous etes peut etre intéressé: « Comment fonctionnent les neurones? »
Quels sont-ils et comment fonctionnent-ils exactement ?
Maintenant que nous avons vu l'idée générale de ce que sont les réseaux de neurones et que nous allons mieux comprendre ce qu'ils sont et comment ces émulateurs des neurones du cerveau humain fonctionnent et où les réseaux de neurones profonds peignent-ils dans tout cela processus.
Imaginons que nous ayons le réseau neuronal suivant: nous avons trois couches de neurones artificiels. Disons que la première couche a 4 neurones ou nœuds, la seconde 3 et la dernière n'en a que 2. Tout cela est un exemple de réseau de neurones artificiels, assez facile à comprendre.
La première couche est celle qui reçoit les données., c'est-à-dire les informations qui peuvent très bien se présenter sous forme de son, d'image, d'arômes, d'impulsions électriques... Cette première la couche est la couche d'entrée, et est en charge de recevoir toutes les données pour pouvoir les envoyer plus tard à la suivante couches. Lors de la formation de notre réseau de neurones, ce sera la couche avec laquelle nous allons travailler en premier, lui donnant les données que nous utiliserons pour voir dans quelle mesure vous faites des prédictions ou identifiez les informations qui vous sont fournies donne.
La deuxième couche de notre modèle hypothétique est la couche cachée, qui se trouve juste au milieu des première et dernière couches., comme si notre réseau neuronal était un sandwich. Dans cet exemple, nous n'avons qu'un seul calque masqué, mais il peut y en avoir autant que nous le voulons. On pourrait parler de 50, 100, 1000 voire 50 000 couches. Essentiellement, ces couches cachées sont la partie du réseau neuronal que nous appellerions le réseau neuronal profond. Plus la profondeur est grande, plus le réseau de neurones est complexe.
Enfin nous avons la troisième couche de notre exemple qui est la couche de sortie. Cette couche, comme son nom l'indique, est chargé de recevoir les informations des couches précédentes, de prendre une décision et de nous donner une réponse ou un résultat.
Dans le réseau de neurones, chaque neurone artificiel est connecté à tous les suivants. Dans notre exemple, où nous avons commenté que nous avons trois couches de 4, 3 et 2 neurones, les 4 de la couche d'entrée sont connecté avec le 3 de la couche cachée, et le 3 de la couche cachée avec le 2 de la sortie, nous donnant un total de 18 Connexions.
Tous ces neurones sont connectés avec ceux de la couche suivante, envoyant les informations dans le sens entrée->caché->sortie.. S'il y avait plus de couches cachées, on parlerait d'un plus grand nombre de connexions, envoyant les informations de couche cachée à couche cachée jusqu'à ce qu'elles atteignent la couche de sortie. La couche de sortie, une fois qu'elle a reçu l'information, ce qu'elle va faire, c'est nous donner un résultat basé sur l'information qu'elle a reçue et sa façon de la traiter.
Lorsque nous entraînons notre algorithme, c'est-à-dire notre réseau de neurones, ce processus que nous venons d'expliquer va se répéter plusieurs fois. Nous allons livrer des données au réseau, nous allons voir ce que nous donne le résultat et nous allons l'analyser et le comparer avec ce que nous attendions du résultat. S'il y a une grande différence entre ce qui est attendu et ce qui est obtenu, cela signifie qu'il y a une grande marge d'erreur et que, par conséquent, il est nécessaire d'apporter quelques modifications.
Comment fonctionnent les neurones artificiels ?
Nous allons maintenant comprendre le fonctionnement individuel des neurones qui fonctionnent au sein d'un réseau de neurones. Le neurone reçoit une entrée d'informations du neurone précédent. Disons que ce neurone reçoit trois entrées d'informations, chacune provenant des trois neurones de la couche précédente. A son tour, ce neurone génère des sorties, dans ce cas disons qu'il n'est connecté qu'à un neurone de la couche suivante.
Chaque connexion que ce neurone a avec les trois neurones de la couche précédente apporte une valeur "x", qui est la valeur que le neurone précédent nous envoie.; et il a aussi une valeur "w", qui est le poids de cette connexion. Le poids est une valeur qui nous aide à donner plus d'importance à une connexion par rapport aux autres. En bref, chaque connexion avec les neurones précédents a une valeur "x" et une valeur "w", qui sont multipliées (x·w).
Nous allons également avoir une valeur appelée "bias" ou biais représenté par "b" qui est le nombre d'erreur qui incite certains neurones à s'activer plus facilement que d'autres. De plus, nous avons une fonction d'activation au sein du neurone, c'est ce qui fait son degré de classification des différents éléments (p. ex., oranges) n'est pas linéaire. A lui seul, chaque neurone a des paramètres différents à prendre en compte, ce qui fait que l'ensemble du système, c'est le réseau de neurones, se classe de manière non linéaire.
Comment le neurone sait-il s'il doit s'activer ou non? c'est-à-dire, quand savez-vous si vous devez envoyer des informations à la couche suivante? Eh bien, cette décision est régie par l'équation suivante :
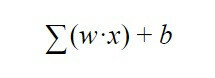
Cette formule signifie qu'il faut faire la somme de tous les poids "w" multipliés par toutes les valeurs de "x" que le neurone reçoit de la couche précédente. A cela s'ajoute le biais "b".
Le résultat de cette équation est envoyé à une fonction d'activation, qui est simplement une fonction qui nous dit que, si le résultat de cette équation est supérieur à un certain nombre, le neurone enverra un signal à la couche suivante et, s'il est inférieur, il ne le fera pas pour l'envoyer Voici donc comment un neurone artificiel décide d'envoyer ou non des informations aux neurones comme suit: couche au moyen d'une sortie que nous appellerons "y", une sortie qui, à son tour, est l'entrée "x" du suivant neurone.
Et comment forme-t-on tout un réseau ?
La première chose à faire est de fournir des données à la première couche, comme nous l'avons déjà commenté. Cette couche enverra des informations aux couches suivantes, qui sont les couches cachées ou le réseau de neurones profond. Les neurones de ces couches s'activeront ou non en fonction des informations reçues. Enfin, la couche de sortie nous donnera un résultat, que nous comparerons avec la valeur que nous attendions pour voir si le réseau de neurones a appris quoi faire correctement.
S'il n'a pas bien appris, nous effectuerons une autre interaction, c'est-à-dire nous vous présenterons à nouveau des informations et verrons comment se comporte le réseau de neurones. En fonction des résultats obtenus, on ajustera les valeurs "b", c'est-à-dire le biais de chaque neurone, et le "w", c'est-à-dire le poids de chaque connexion avec chaque neurone pour réduire l'erreur. Pour connaître la taille de cette erreur, nous allons utiliser une autre équation, qui est la suivante :
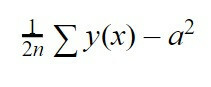
Cette équation est l'erreur quadratique moyenne. Nous allons faire la somme de y (x) qui est la valeur que notre réseau nous a donné dans l'interaction moins "a", qui est la valeur que nous attendions qu'il nous donne, élevée au carré. Enfin, nous allons multiplier cette somme par 1/2n, étant que « n » le nombre d'interactions que nous avons envoyées pour entraîner notre réseau de neurones.
Par exemple, supposons que nous ayons les valeurs suivantes

La première colonne « y(x) » représente ce que notre réseau nous a apporté dans chacune des quatre interactions que nous avons testées. Les valeurs que nous avons obtenues, comme on peut le voir, ne correspondent pas à celles de la deuxième colonne "a", qui sont les valeurs souhaitées pour chacune des interactions testées. La dernière colonne représente l'erreur de chaque interaction.
En appliquant la formule susmentionnée et en utilisant ces données ici, en gardant à l'esprit que dans ce cas n = 4 (4 interactions) nous donne une valeur de 3,87, qui est l'erreur quadratique moyenne que notre réseau de neurones a dans ces des moments. Connaissant l'erreur, ce que nous devons faire maintenant est, comme nous l'avons déjà commenté, de changer le biais et le poids de chacun des neurones et leurs interactions avec l'intention que de cette façon l'erreur est réduire.
À ce stade, les ingénieurs et les informaticiens postulent un algorithme appelé descente de gradient avec lesquels ils peuvent obtenir des valeurs pour tester et modifier le biais et le poids de chaque neurone artificiel de sorte que, de cette manière, une erreur de plus en plus faible est obtenue, se rapprochant de la prédiction ou du résultat recherché. C'est une question de test et plus il y aura d'interactions, plus il y aura de formation et plus le réseau apprendra.
Une fois que le réseau de neurones est correctement formé, il nous fournira des prédictions et des identifications précises et fiables. À ce stade, nous allons avoir un réseau qui aura dans chacun de ses neurones une valeur de poids défini, avec un biais contrôlé et avec une capacité de décision qui rendra le système travail.
Références bibliographiques:
- Puig, A. [AMP Tech] (2017, 28 juillet). Comment fonctionnent les réseaux de neurones? [Fichier vidéo]. Rétabli https://www.youtube.com/watch? v=IQMoglp-fBk&ab_channel=AMPTech
- Santaolalla, J. [Offrez-vous un Vlog] (11 avril 2017) CienciaClip Challenge - Que sont les réseaux de neurones? [Fichier vidéo]. https://www.youtube.com/watch? v=rTpr6DuY4LU&ab_channel=DateunVlog
- Schmidhuber, J. (2015). "Apprentissage en profondeur dans les réseaux de neurones: un aperçu". Les réseaux de neurones. 61: 85–117. arXiv: 1404.7828. doi: 10.1016/j.neunet.2014.09.003. PMID 25462637. S2CID 11715509
