
Dype nevrale nettverk: hva de er og hvordan de fungerer
Dype nevrale nettverk er et konsept som utgjør den viktigste teknologiske arkitekturen som brukes i Deep Learning-modeller. Disse strukturene kan ikke forstås uten å forstå den generelle ideen om kunstige nevrale nettverk, grunnleggende for kunstig intelligens.
Nevrale nettverk brukes til tusen ting: å gjenkjenne nummerskilt, sanger, ansikter, stemmer eller til og med fruktene på kjøkkenet vårt. De er en spesielt nyttig teknologi, og til tross for at de først nylig har blitt praktiske, kommer de til å bli menneskehetens fremtid.
Neste Vi kommer til å se i dybden ideen om kunstige nevrale nettverk og dype, forstå hvordan de fungerer, hvordan de trenes og hvordan interaksjonene mellom de forskjellige nevronene som utgjør dem oppstår.
- Relatert artikkel: "Hva er kognitiv vitenskap? Dens grunnleggende ideer og utviklingsfaser"
Hva er dype nevrale nettverk og hva kjennetegner dem?
Dype nevrale nettverk er en av de viktigste teknologiske arkitekturene som brukes i Deep Learning eller Deep Learning. Disse spesielle kunstige nettverkene har hatt en svimlende vekst de siste årene fordi de utgjør et grunnleggende aspekt når det gjelder å gjenkjenne alle slags mønstre. Kunstig intelligens eksisterer takket være driften av disse spesielle nettverkene som, i I hovedsak kommer de til å være en kopi av hvordan hjernen vår fungerer, selv om den er i en teknologisk og matte.
Før vi går videre inn på hva dype nevrale nettverk er, må vi først forstå hvordan kunstige nevrale nettverk fungerer generelt og hva de er til for. Lnevrale nettverk er en gren av "Machine Learning" som har hatt en enorm innvirkning de siste årene, hjelper programmerere og datavitere med å bygge ting som chatbots som, når vi snakker med dem, får oss til å tro at vi snakker med ekte mennesker.
Kunstige nevrale nettverk har også blitt brukt med selvkjørende biler, mobilapplikasjoner som gjenkjenner ansiktet vårt og forvandler det til det vi vil ha og mange flere funksjoner. Dens anvendelighet er svært omfattende, og tjener som grunnlaget for moderne kunstig intelligens og har uendelige fordelaktige bruksområder for vår dag til dag.
kunstige nevrale nettverk
La oss forestille oss at vi er på kjøkkenet vårt og vi bestemmer oss for å se etter en appelsin, en veldig enkel oppgave.. Vi vet å identifisere en appelsin veldig enkelt, og vi vet også hvordan vi skiller den fra andre frukter som vi finner på kjøkkenet, som bananer, epler og pærer. Som? For i hjernen vår har vi veldig assimilert det som er de typiske egenskapene til en appelsin: dens størrelsen, formen, fargen den har, hvordan den lukter... Dette er alle parametere vi bruker for å finne en oransje.
Det er en enkel oppgave for mennesker, men... Kan en datamaskin også gjøre det? Svaret er ja. I prinsippet vil det være nok å definere de samme parametrene og tilordne en verdi til en node eller noe som vi godt kan kalle en "kunstig nevron". Vi vil fortelle den nevronen hvordan appelsiner er, og indikerer størrelse, vekt, form, farge eller andre parametere som vi tilskriver denne frukten. Etter å ha denne informasjonen, forventes det at nevronet vil vite hvordan man identifiserer en appelsin når den presenteres med en.
Hvis vi har valgt parametrene godt, vil det være enkelt for deg å skille mellom appelsiner og ting som ikke er appelsiner bare ved å ta hensyn til disse egenskapene. Når det presenteres et bilde av en frukt, vil det nevronet søke etter egenskapene knyttet til appelsinen og bestemmer om du vil inkludere den i kategorien "oransje" eller i kategorien "annet". frukt". I statistiske termer vil det være å finne en region i en parametergraf som tilsvarer det som blir ser etter en region som vil omfatte alle fruktbitene som deler samme størrelse, form, farge, vekt og aroma som appelsiner.
Til å begynne med høres alt dette veldig enkelt ut å kode, og det er det faktisk. Det fungerer veldig bra å skille en appelsin fra en banan eller et eple, siden de har forskjellige farger og former. Men hva om vi ga deg en grapefrukt? og en veldig stor mandarin? De er frukter som perfekt kan forveksles med en appelsin. Vil det kunstige nevronet selv kunne skille mellom appelsiner og grapefrukter? Svaret er nei, og faktisk antas de sannsynligvis å være de samme.
Problemet med å bruke bare ett lag med kunstige nevroner, eller hva som er det samme, bare bruke enkle nevroner først, er at generere svært upresise beslutningsgrenser når du blir presentert for noe som har mange kjennetegn til felles med det du burde kunne gjenkjenne, men i virkeligheten er det ikke det. Hvis vi presenterer noe som ser ut som en appelsin, for eksempel en grapefrukt, selv om det ikke er den frukten, vil det identifisere det som det.
Disse beslutningsgrensene, hvis de er representert i form av en graf, vil alltid være lineære. Ved å bruke en enkelt kunstig nevron, det vil si en enkelt node som har integrerte parametere konkrete, men ikke kan lære utover dem, vil man få svært nære beslutningsgrenser. diffuse. Hovedbegrensningen er at den bruker to statistiske metoder, spesifikt multiklasseregresjon og logistisk regresjon, som betyr at når du er i tvil, inkluderer den noe som ikke er det vi forventet at det skulle være. vil identifisere.
Hvis vi skulle dele all frukt i "appelsiner" og "ikke appelsiner", med bare ett nevron, er det klart at bananer, pærer, epler, vannmeloner og enhver frukt som ikke samsvarer i størrelse, farge, form, aroma og så videre med appelsiner, jeg ville satt dem i "nei"-kategorien. appelsiner». Imidlertid vil grapefrukt og mandariner sette dem i kategorien "appelsiner", og gjøre jobben de er dårlig designet for.
Og når vi snakker om appelsiner og grapefrukt kan vi godt snakke om hunder og ulver, høner og høner, bøker og notatbøker... Alle Disse situasjonene er tilfeller der en enkel serie med "hvis..." ("hvis...") ikke vil være tilstrekkelig for å skille klart mellom det ene og det andre. annen. Det trengs et mer komplekst, ikke-lineært system, som er mer presist når det gjelder å skille mellom ulike elementer. Noe som tar høyde for at mellom likhetene kan det være forskjeller. Det er her nevrale nettverk kommer inn.
Flere lag, mer lik den menneskelige hjernen
Kunstige nevrale nettverk, som navnet antyder, er kunstige beregningsmodeller inspirert av i de nevrale nettverkene i den menneskelige hjernen, nettverk som faktisk etterligner funksjonen til dette organet biologiske. Dette systemet er inspirert av nevrale funksjoner og dets hovedapplikasjon er gjenkjennelse av mønstre av alle slag: ansiktsidentifikasjon, stemmegjenkjenning, fingeravtrykk, håndskrift, bilskilt… Mønstergjenkjenning fungerer for nesten alt..
Siden det er forskjellige nevroner, er parametrene som brukes forskjellige og en høyere grad av presisjon oppnås. Disse nevrale nettverkene er systemer som lar oss dele elementer inn i kategorier når forskjellen kan være subtil, og skille dem på en ikke-lineær måte, noe som ellers ville være umulig å gjøre måte.
Med en enkelt node, med en enkelt nevron, er det som gjøres når du håndterer informasjonen en multiklasseregresjon. Ved å legge til flere nevroner, siden hver og en av dem har sin egen ikke-lineære aktiveringsfunksjon som, oversatt til enklere språk, gjør at de har beslutningsgrenser som er mer presis, ved å være grafisk representert i en buet form og ta hensyn til flere egenskaper når man skiller mellom "appelsiner" og "ikke appelsiner", for å fortsette med det eksemplet.
Krumningen til disse beslutningsgrensene vil direkte avhenge av hvor mange lag med nevroner vi legger til vårt nevrale nettverk. Disse lagene av nevroner, som gjør systemet mer komplekst og mer presist, er i realiteten dype nevrale nettverk. I prinsippet, jo flere lag med dype nevrale nettverk vi har, jo mer nøyaktig og likt vil programmet være sammenlignet med den menneskelige hjernen.
Kort sagt, nevrale nettverk er ikke annet enn et intelligent system som lar mer presise avgjørelser tas, på en veldig lik måte som vi mennesker gjør det. Mennesker er basert på erfaring og lærer av miljøet vårt. For eksempel, gå tilbake til tilfellet med appelsin og grapefrukt, hvis vi aldri har sett en, vil vi perfekt forveksle det med en appelsin. Når vi har blitt kjent med det, vil det være da vi allerede vet hvordan vi skal identifisere det og skille det fra appelsiner.
Det første som gjøres er å gi noen parametere til de nevrale nettverkene slik at de vet hvordan det er som vi vil at det skal lære å identifisere. Deretter kommer lærings- eller treningsfasen, slik at den blir stadig mer nøyaktig og gradvis har en mindre feilmargin. Dette er tiden da vi ville presentere vårt nevrale nettverk med en appelsin og andre frukter. I opplæringsfasen vil de få tilfeller der de er oransje og tilfeller der de ikke er oransje, for å se om de har svaret riktig og fortelle dem det riktige svaret.
Vi vil prøve å gjøre mange forsøk og så nær virkeligheten som mulig.. På denne måten hjelper vi det nevrale nettverket til å operere når virkelige tilfeller kommer, og det vet hvordan det skal diskriminere riktig, på samme måte som et menneske ville gjort i det virkelige liv. Hvis opplæringen har vært tilstrekkelig, etter å ha valgt gode gjenkjennelsesparametere og har klassifisert godt, kommer det nevrale nettverket til å ha en svært høy suksessrate for mønstergjenkjenning. høy.
- Du kan være interessert i: "Hvordan fungerer nevroner?"
Hva er de og hvordan fungerer de nøyaktig?
Nå som vi har sett den generelle ideen om hva nevrale nettverk er, og vi kommer til å forstå mer fullstendig hva de er og hvordan disse emulatorene av nevronene i den menneskelige hjernen fungerer, og hvor maler dype nevrale nettverk i alt dette prosess.
La oss forestille oss at vi har følgende nevrale nettverk: vi har tre lag med kunstige nevroner. La oss si at det første laget har 4 nevroner eller noder, det andre 3, og det siste har bare 2. Alt dette er et eksempel på et kunstig nevralt nettverk, ganske enkelt å forstå.
Det første laget er det som mottar dataene., det vil si informasjonen som godt kan komme i form av lyd, bilde, aromaer, elektriske impulser... Denne første lag er inngangslaget, og har ansvaret for å motta all data for senere å kunne sende den til følgende lag. Under treningen av vårt nevrale nettverk vil dette være laget vi først skal jobbe med, og gi det data som vi vil bruke for å se hvor god du er til å forutsi eller identifisere informasjonen du får gir.
Det andre laget i vår hypotetiske modell er det skjulte laget, som sitter rett i midten av det første og siste laget., som om vårt nevrale nettverk var en sandwich. I dette eksemplet har vi bare ett skjult lag, men det kan være så mange vi vil. Vi kan snakke om 50, 100, 1000 eller til og med 50 000 lag. I hovedsak er disse skjulte lagene den delen av det nevrale nettverket som vi vil kalle det dype nevrale nettverket. Jo større dybden er, desto mer komplekst er det nevrale nettverket.
Til slutt har vi det tredje laget i eksemplet vårt som er utgangslaget. Dette laget, som navnet indikerer, har ansvar for å motta informasjon fra de foregående lagene, ta en beslutning og gi oss et svar eller resultat.
I det nevrale nettverket er hvert kunstig nevron koblet til alle de følgende. I vårt eksempel, hvor vi har kommentert at vi har tre lag med 4, 3 og 2 nevroner, er de 4 i inngangslaget koblet til 3 i det skjulte laget, og 3 i det skjulte laget med 2 i utgangen, noe som gir oss totalt 18 forbindelser.
Alle disse nevronene er forbundet med de i neste lag, og sender informasjonen i input->skjult-> utgangsretning.. Hvis det var flere skjulte lag, ville vi snakket om et større antall tilkoblinger, og sendte informasjonen fra skjult lag til skjult lag til den når utdatalaget. Utdatalaget, når det har mottatt informasjonen, vil det gjøre å gi oss et resultat basert på informasjonen den har mottatt og måten å behandle den på.
Når vi trener algoritmen vår, det vil si vårt nevrale nettverk, kommer denne prosessen som vi nettopp har forklart til å bli gjort mange ganger. Vi skal levere noen data til nettverket, vi skal se hva resultatet gir oss og vi skal analysere det og sammenligne det med det vi forventet at resultatet skulle gi oss. Hvis det er stor forskjell mellom det som forventes og det som oppnås, betyr det at det er høy feilmargin og at det derfor er nødvendig å gjøre noen få modifikasjoner.
Hvordan fungerer kunstige nevroner?
Nå skal vi forstå den individuelle funksjonen til nevronene som jobber innenfor et nevralt nettverk. Nevronet mottar et input med informasjon fra det forrige nevronet. La oss si at dette nevronet mottar tre informasjonsinnganger, som hver kommer fra de tre nevronene i det forrige laget. I sin tur genererer dette nevronet utganger, i dette tilfellet la oss si at det bare er koblet til et nevron i neste lag.
Hver forbindelse som dette nevronet har med de tre nevronene i det forrige laget gir en "x"-verdi, som er verdien som det forrige nevronet sender oss.; og den har også en verdi "w", som er vekten av denne forbindelsen. Vekt er en verdi som hjelper oss å legge mer vekt på én forbindelse fremfor andre. Kort sagt, hver forbindelse med de forrige nevronene har en "x" og en "w" verdi, som multipliseres (x·w).
Det skal vi også ha en verdi kalt "bias" eller bias representert med "b" som er antallet feil som oppmuntrer enkelte nevroner til å aktiveres lettere enn andre. I tillegg har vi en aktiveringsfunksjon i nevronet, som er det som gjør graden av klassifisering av forskjellige elementer (s. appelsiner) er ikke lineær. På egen hånd har hver nevron forskjellige parametere å ta hensyn til, noe som gjør at hele systemet, dette er det nevrale nettverket, klassifiseres på en ikke-lineær måte.
Hvordan vet nevronet om det må aktiveres eller ikke? det vil si når vet du om du må sende informasjon til neste lag? Vel, denne avgjørelsen styres av følgende ligning:
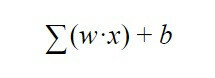
Denne formelen kommer til å bety at summen av alle vektene "w" multiplisert med alle verdiene av "x" som nevronet mottar fra forrige lag, må lages. I tillegg til dette legges skjevheten "b".
Resultatet av denne ligningen sendes til en aktiveringsfunksjon, som ganske enkelt er en funksjon som forteller oss at hvis resultatet av denne ligningen er større enn a et visst antall, vil nevronet sende et signal til neste lag, og hvis det er mindre, vil det ikke å sende den Så dette er hvordan et kunstig nevron bestemmer om det skal sendes informasjon til nevronene som følger: lag ved hjelp av en utgang som vi vil kalle "y", en utgang som igjen er inngangen "x" til følgende nevron.
Og hvordan trener du et helt nettverk?
Det første som gjøres er å levere data til det første laget, som vi tidligere har kommentert. Dette laget vil sende informasjon til følgende lag, som er de skjulte lagene eller det dype nevrale nettverket. Nevronene i disse lagene vil aktiveres eller ikke, avhengig av informasjonen som mottas. Til slutt vil utdatalaget gi oss et resultat, som vi vil sammenligne med verdien vi ventet på for å se om det nevrale nettverket har lært hva det skal gjøre riktig.
Hvis han ikke lærte godt, vil vi utføre en annen interaksjon, det vil si vi vil presentere informasjon på nytt og se hvordan det nevrale nettverket oppfører seg. Avhengig av resultatene som oppnås, vil "b"-verdiene bli justert, det vil si skjevheten til hvert nevron, og "w", dette er vekten av hver forbindelse med hver nevron for å redusere feilen. For å finne ut hvor stor feilen er, skal vi bruke en annen ligning, som er følgende:
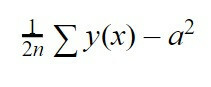
Denne ligningen er rotmiddelkvadratfeilen. Vi skal gjøre summen av y (x) som er verdien som nettverket vårt ga oss i interaksjonen minus "a", som er verdien vi forventet at det skulle gi oss, hevet til kvadratet. Til slutt skal vi multiplisere denne summen med 1/2n, som er det "n" antallet interaksjoner som vi har sendt for å trene vårt nevrale nettverk.
Anta for eksempel at vi har følgende verdier

Den første kolonnen "y (x)" representerer hva nettverket vårt har gitt oss i hver av de fire interaksjonene vi har testet det. Verdiene som vi har oppnådd, samsvarer ikke med verdiene i den andre kolonnen "a", som er de ønskede verdiene for hver av de testede interaksjonene. Den siste kolonnen representerer feilen for hver interaksjon.
Bruk den nevnte formelen og bruk disse dataene her, og husk at i dette tilfellet er n = 4 (4 interaksjoner) gir oss en verdi på 3,87, som er den gjennomsnittlige kvadratfeilen som vårt nevrale nettverk har i disse øyeblikk. Når vi kjenner til feilen, er det vi må gjøre nå, som vi har kommentert før, endre skjevheten og vekter av hver enkelt av nevronene og deres interaksjoner med den hensikt at på denne måten er feilen redusere.
På dette tidspunktet søker ingeniører og datavitere en algoritme kalt gradient descent som de kan oppnå verdier for å teste og modifisere skjevheten og vekten til hvert kunstig nevron slik at det på denne måten oppnås en stadig lavere feil som nærmer seg prediksjonen eller resultatet ønsket. Det er et spørsmål om å teste og jo flere interaksjoner som gjøres, jo mer trening blir det og jo mer lærer nettverket.
Når det nevrale nettverket er tilstrekkelig trent, vil det være når det vil gi oss nøyaktige og pålitelige spådommer og identifiseringer. På dette tidspunktet skal vi ha et nettverk som vil ha i hver av sine nevroner en verdi på definert vekt, med en kontrollert skjevhet og med en beslutningskapasitet som vil gjøre systemet arbeid.
Bibliografiske referanser:
- Puig, A. [AMP Tech] (2017, 28. juli). Hvordan fungerer nevrale nettverk? [Videofil]. Kommet seg fra https://www.youtube.com/watch? v=IQMoglp-fBk&ab_channel=AMPTech
- Santaolalla, J. [Gi deg selv en vlogg] (2017, 11. april) CienciaClip Challenge - Hva er nevrale nettverk? [Videofil]. https://www.youtube.com/watch? v=rTpr6DuY4LU&ab_channel=DateunVlog
- Schmidhuber, J. (2015). "Dyp læring i nevrale nettverk: en oversikt". Nevrale nettverk. 61: 85–117. arXiv: 1404.7828. doi: 10.1016/j.neunet.2014.09.003. PMID 25462637. S2CID 11715509


